|
|
Preprints |
|
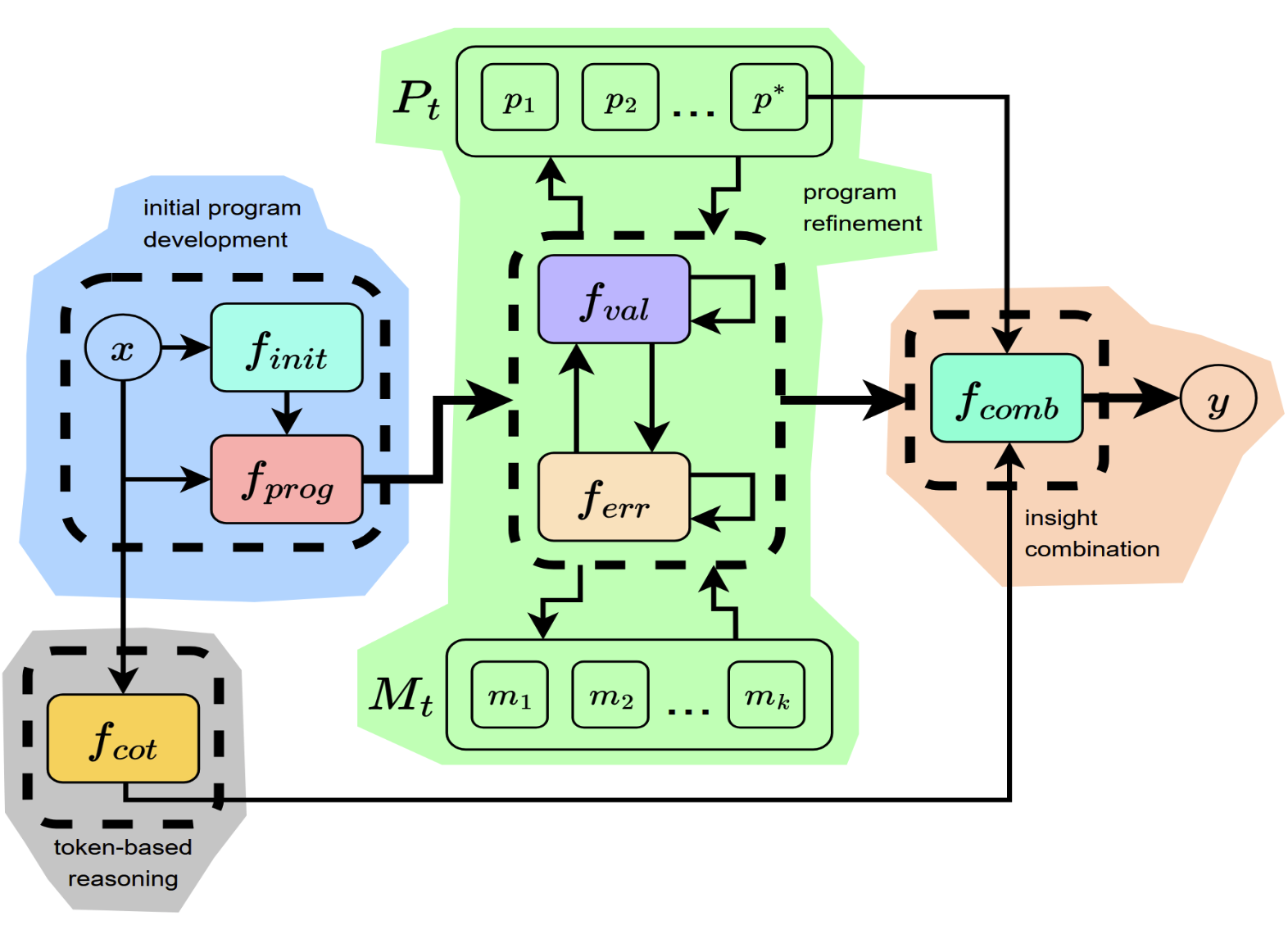
A. Basarkar, B. Tabarsi, T. Barnes, D. Xu [arXiv 2026] arXiv:2602.03950 Paper / Code We introduce Iteratively Improved Program Construction (IIPC), an execution-driven reasoning method that iteratively refines programmatic reasoning chains while preserving token-level contextual reasoning for mathematical problem solving. |
|
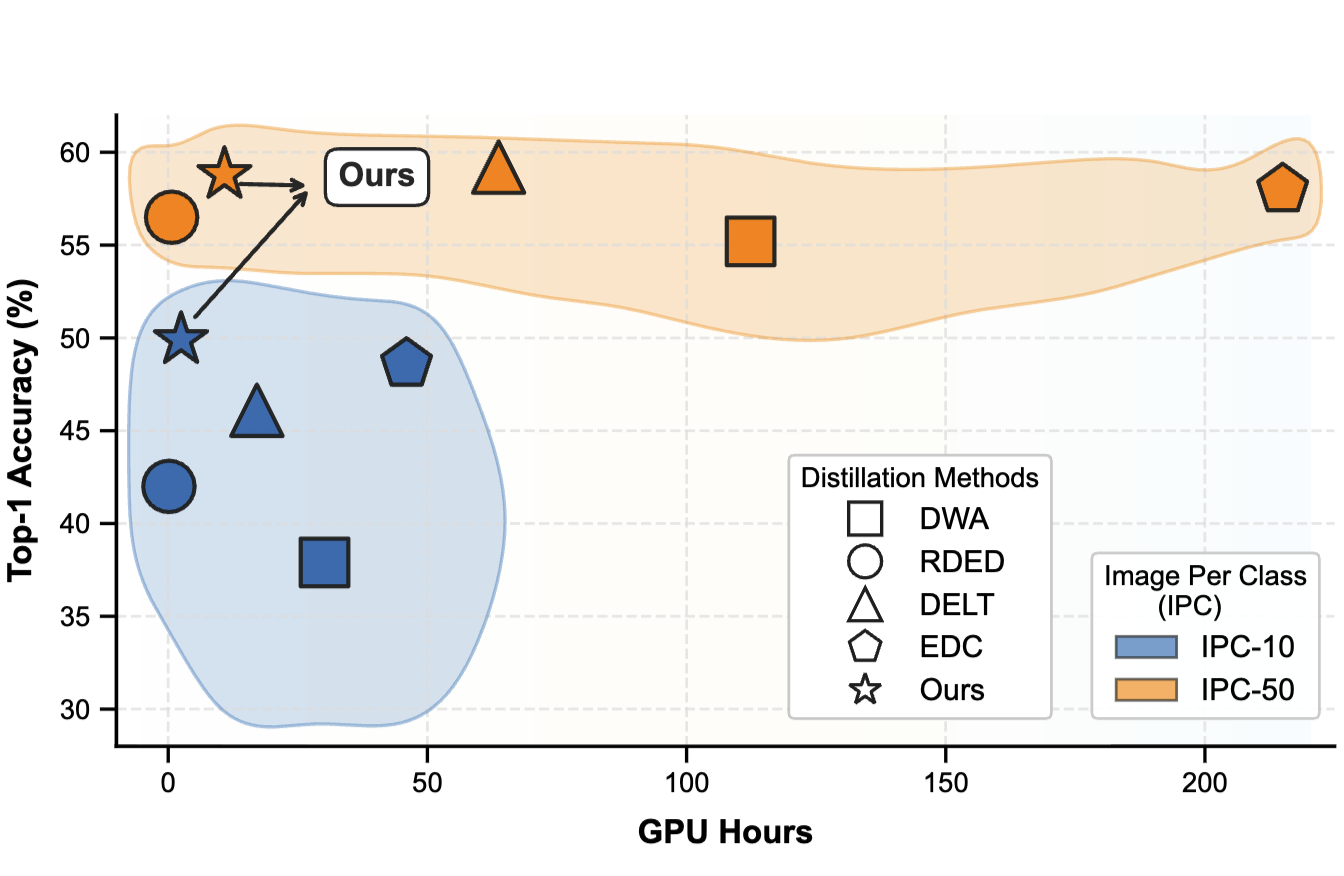
M. J. Alahmadi, P. Gao, F. Wang, D. Xu [arXiv 2026] arXiv:2602.15277 Paper / Code We propose Exploration-Exploitation Distillation (E2D), a practical large-scale dataset distillation method that reduces redundant computation through full-image initialization and a two-phase optimization strategy, achieving stronger accuracy-efficiency trade-offs on ImageNet benchmarks. |
|
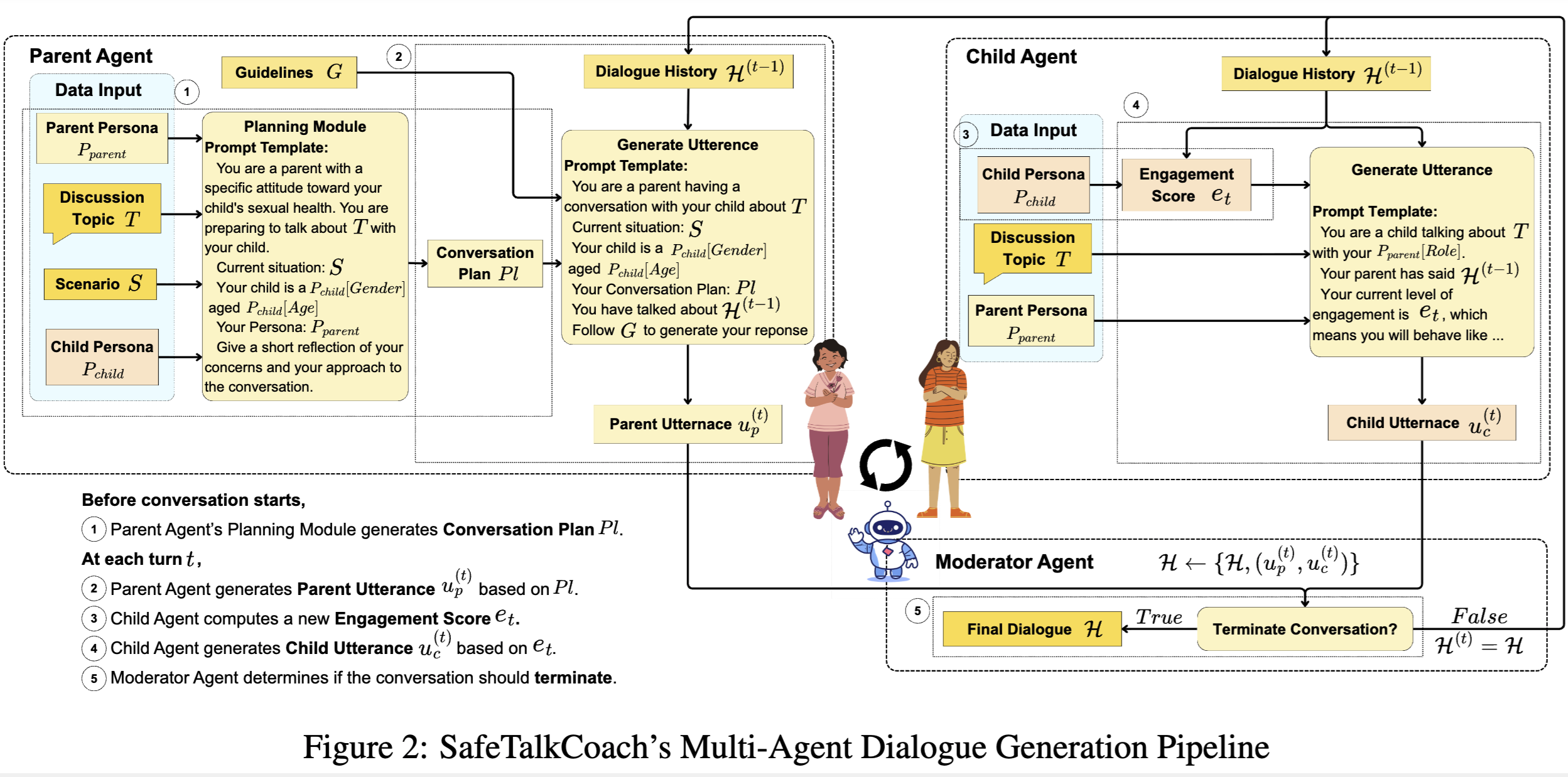
B. Tabarsi, W. Li, T. Yasir, A. S. Kumar, L. Widman, D. Xu, T. Barnes [arXiv 2026] arXiv:2602.00017 Paper We introduce SafeTalkCoach, a diversity-driven multi-agent framework for simulating realistic, guideline-grounded parent-teen conversations about sexual health, together with a dataset supporting AI and health communication research. |

|
H. Ma, H. Gong, X. Yi, X. Xie, D. Xu [arXiv 2025] arXiv:2503.20182 Paper / Code We propose Core Sentiment Inventory (CSI), a bilingual implicit evaluation framework for quantifying LLMs’ emotional tendencies. CSI improves reliability and predictive validity compared with traditional evaluation methods, revealing nuanced sentiment patterns across languages and contexts. |
|
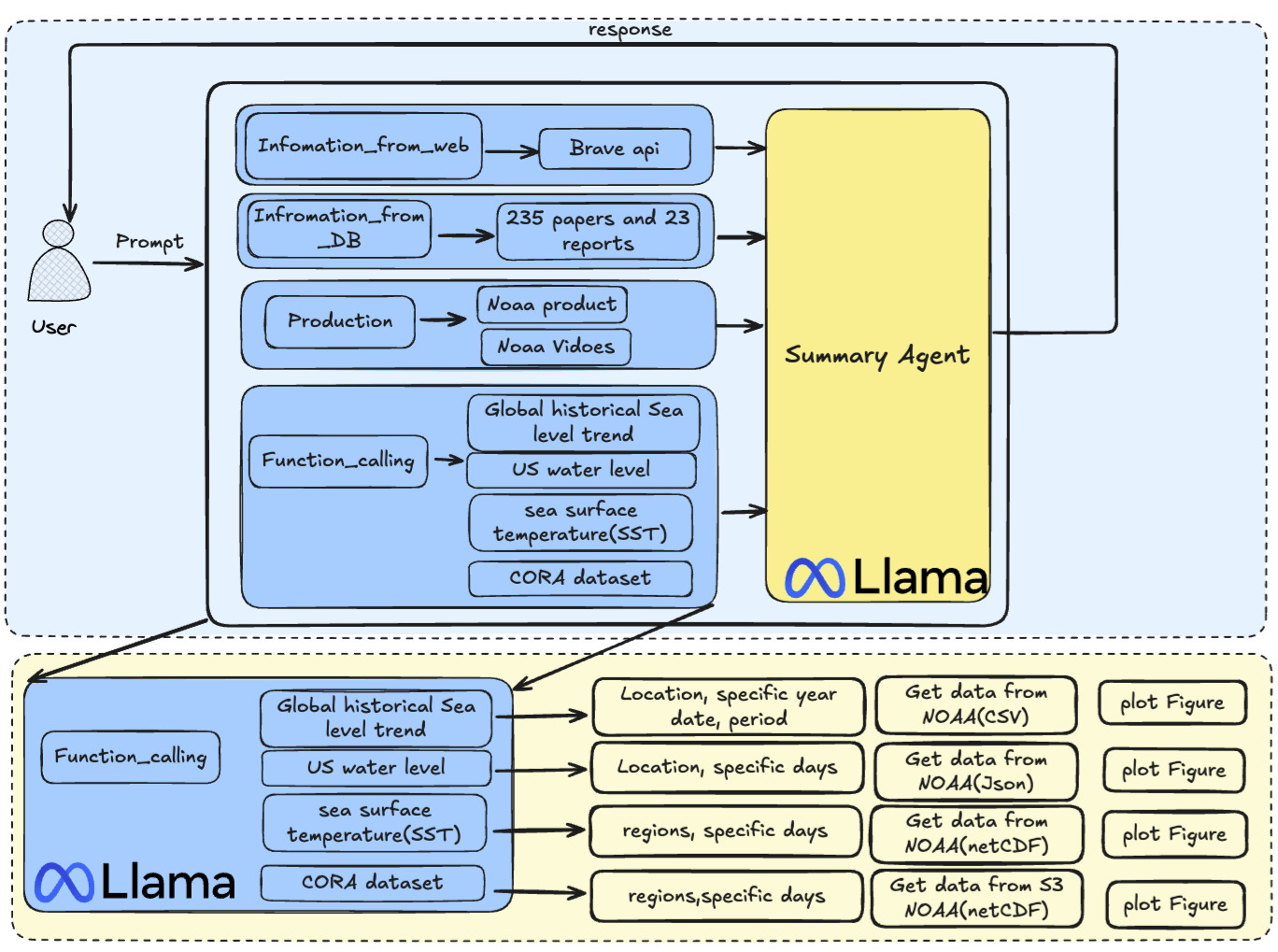
B. Chen, J. Gajbhar, G. Dusek, R. Redmon, P. Hogan, P. Liu, D. Bohnenstiehl, D. Xu, R. He [arXiv 2025] arXiv:2511.01019 Paper / Platform We present OceanAI, a conversational platform that combines open-source LLMs with real-time access to authoritative NOAA oceanographic data streams to generate accurate, transparent, and reproducible scientific responses and visualizations. |
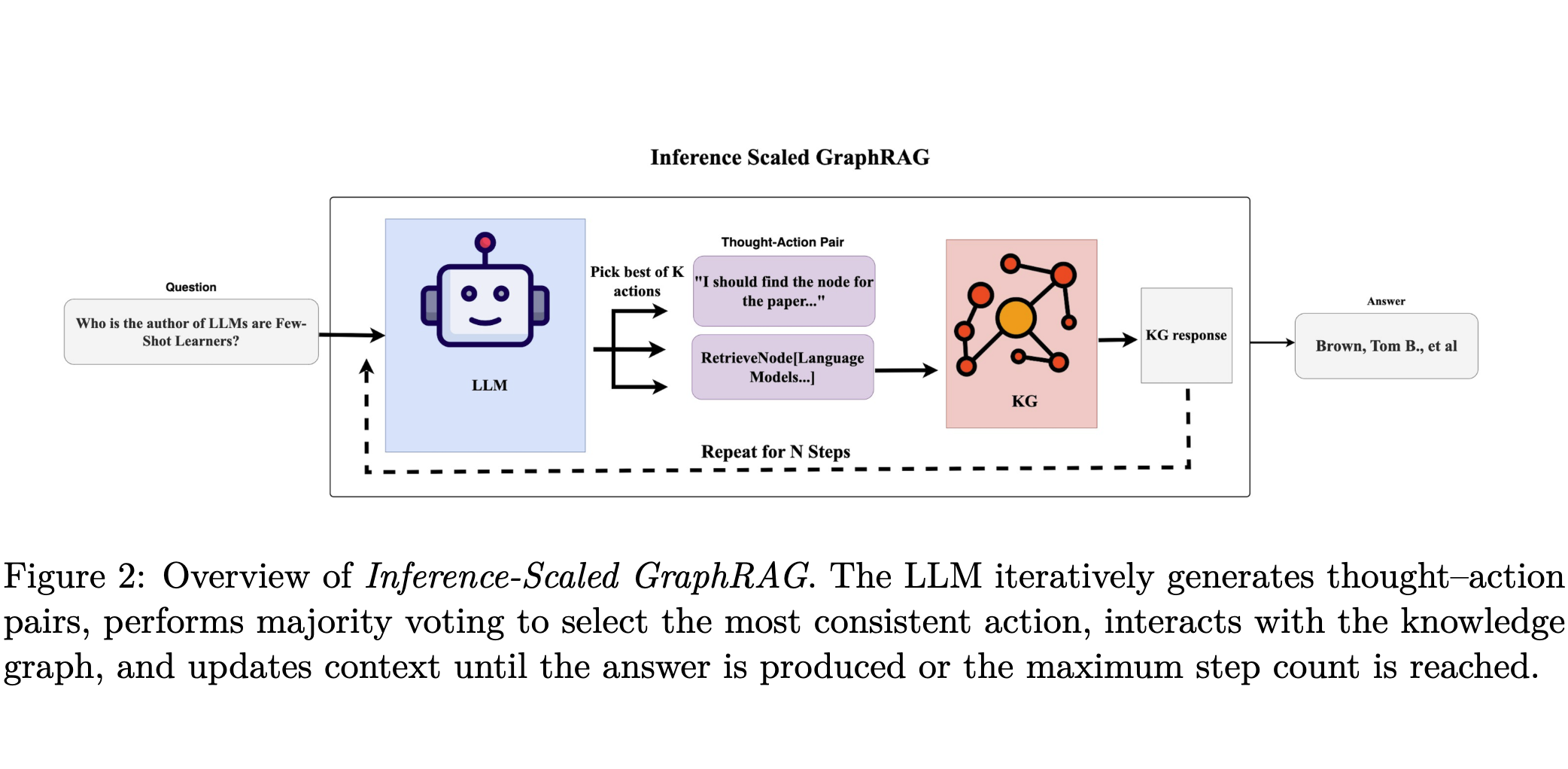
|
T. Thompson, S.-H. Lim, P. Liu, R. He, D. Xu [arXiv 2025] arXiv:2506.19967 Paper We introduce Inference-Scaled GraphRAG, a framework that improves multi-hop question answering on knowledge graphs through inference-time scaling with sequential reasoning, parallel sampling, and majority voting over graph traversal trajectories. |
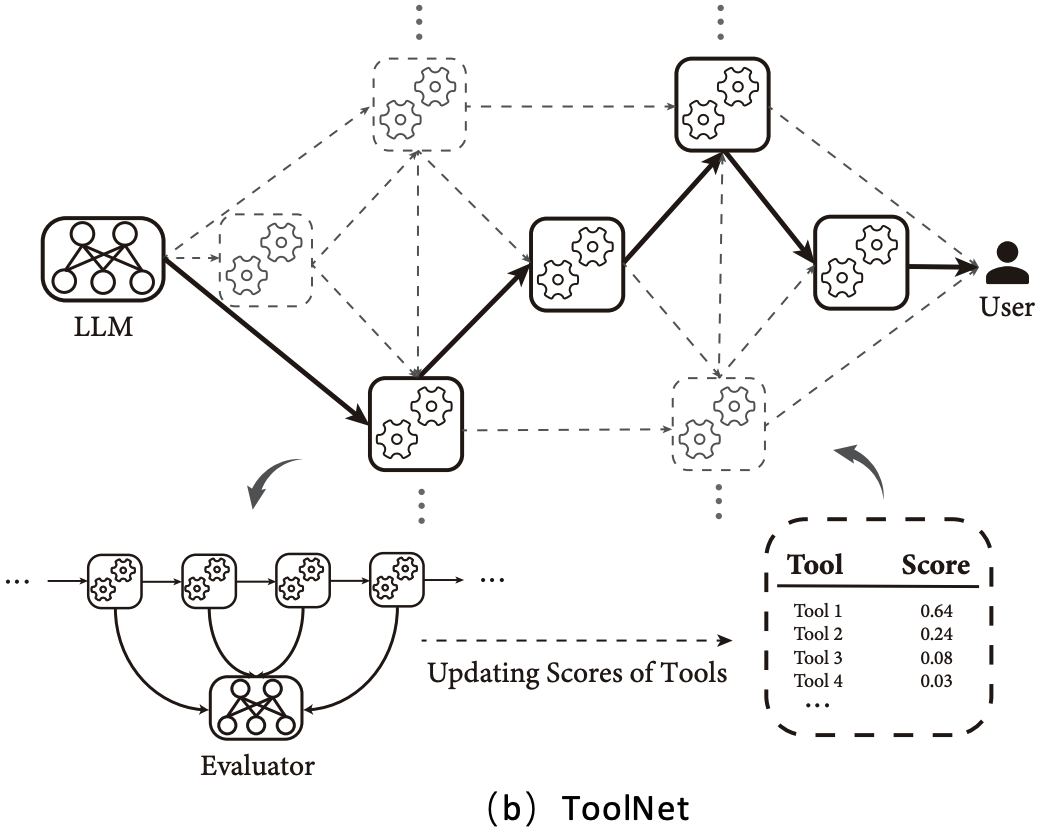
|
X. Liu, Z. Peng, X. Yi, X. Xie, L. Xiang, Y. Liu, D. Xu [arXiv 2024] arXiv:2403.00839 — addressing scalable tool use for large LLM tool ecosystems Paper / Code (to appear) We introduce ToolNet, a graph-based method that enables LLMs to efficiently operate over large tool ecosystems. By modeling tool dependencies as a directed graph with adaptive transition weights, ToolNet improves scalability, robustness, and token efficiency in tool-augmented reasoning. |
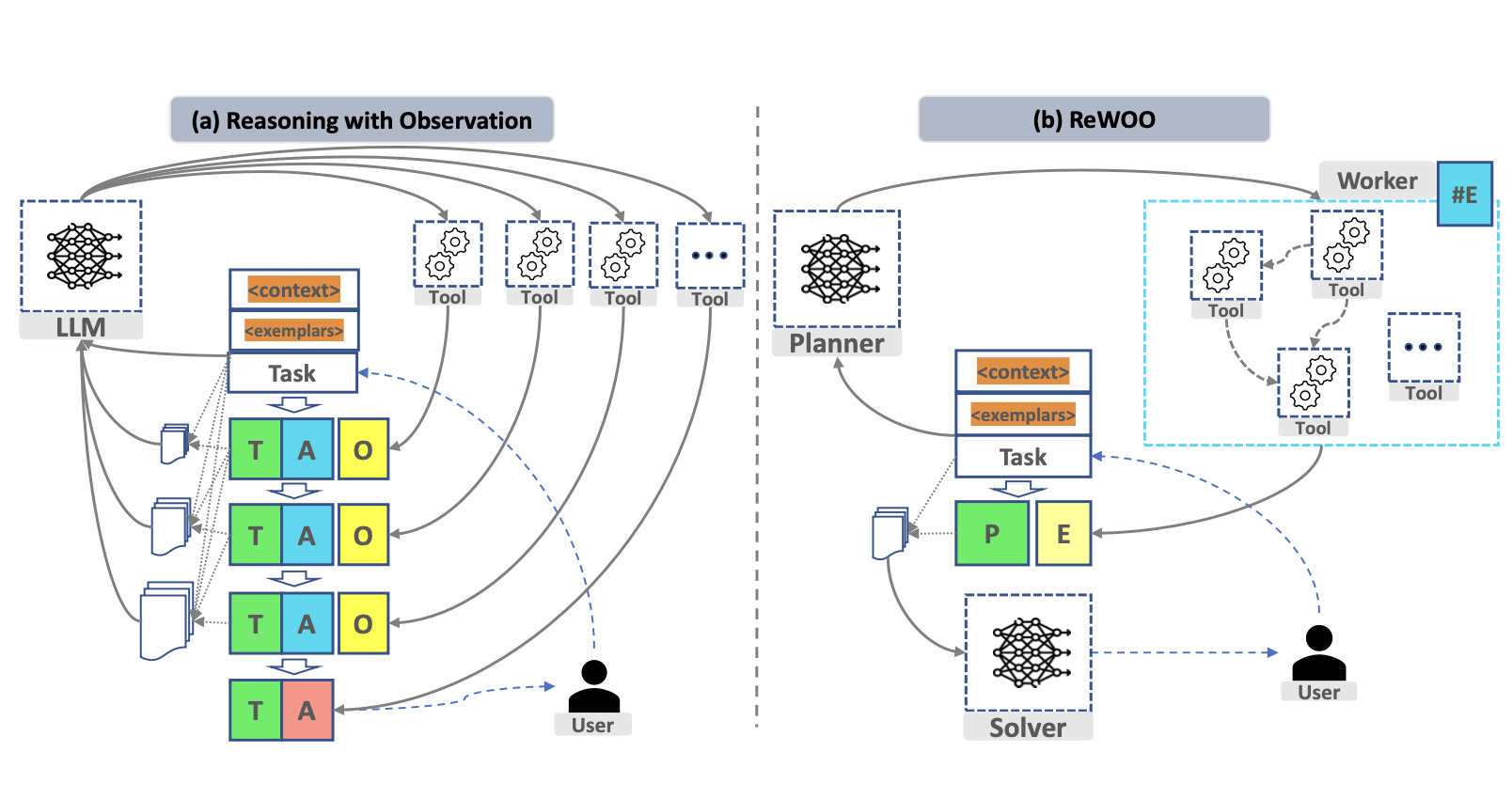
|
B. Xu, Z. Peng, B. Lei, S. Mukherjee, Y. Liu, D. Xu [arXiv 2023] arXiv:2305.18323 — widely used in early LLM agent frameworks Paper / Live Demo / Code / Twitter / Video / Media Coverage / 中文解读 1 / 中文解读 2 We introduce ReWOO, a method for tool-augmented language models that decouples reasoning from external observations. By separating reasoning traces from tool interaction tokens, ReWOO significantly reduces prompt redundancy and improves efficiency for multi-step reasoning with external tools. |
2026 |
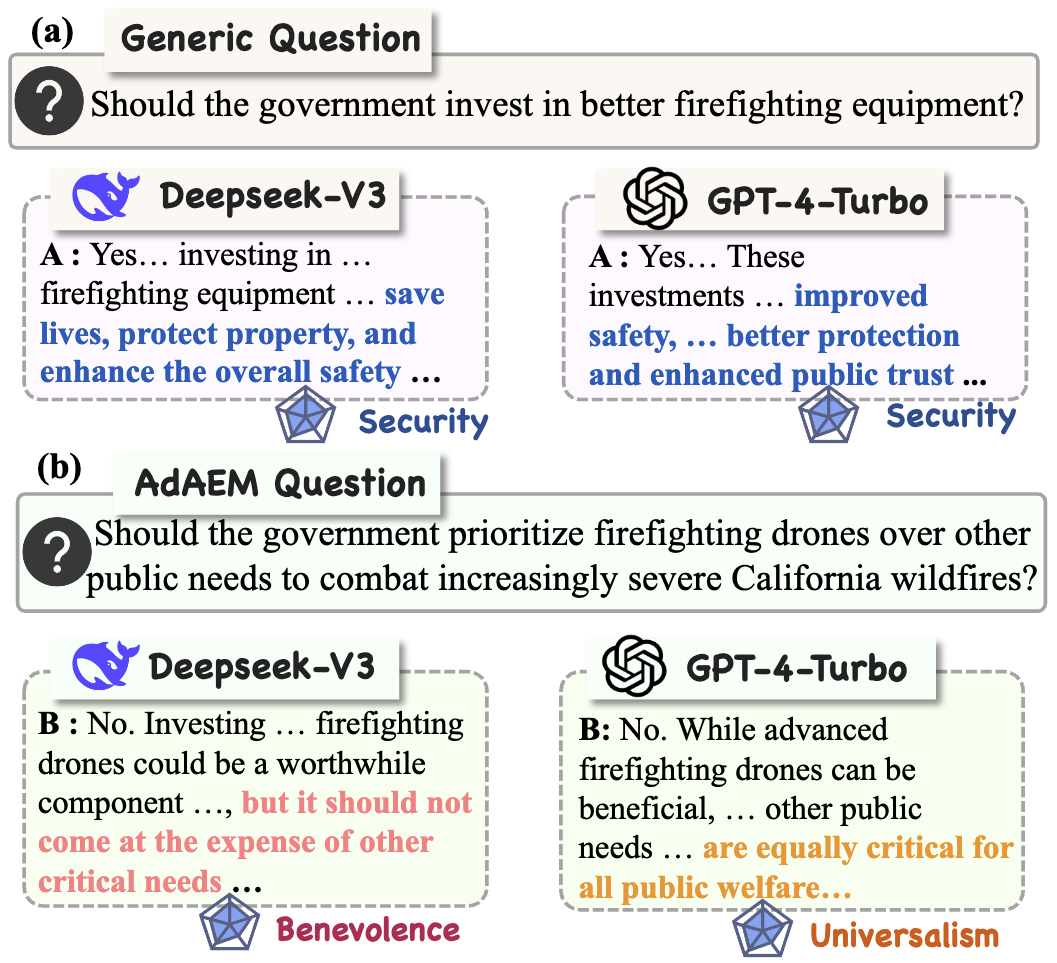
|
J. Yao, S. Duan, X. Yi, D. Xu, P. Zhang, T. Lu, N. Gu, Z. Dou, X. Xie [ICLR 2026] Oral — dynamic evaluation of LLM value differences Paper / Project We introduce AdAEM, a self-extensible evaluation method that automatically generates and refines informative, controversial questions to better reveal value differences across LLMs from diverse cultures and time periods. |
|
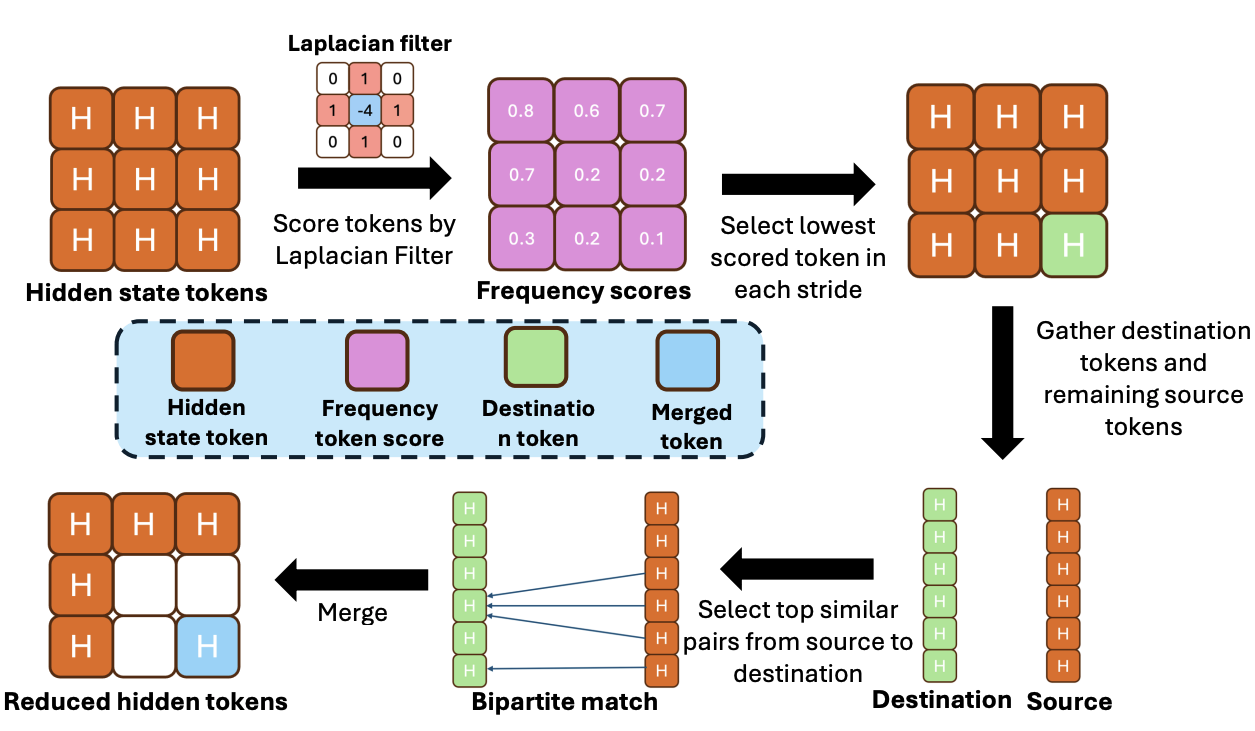
J. Liu, S. Tang, J. Cui, D. Xu, Z. Shen [CVPR 2026] — unified acceleration for generation and classification Paper / Code We propose BiGain, a training-free frequency-aware token compression method for diffusion models that jointly preserves generation quality and improves classification performance under accelerated inference. |
|
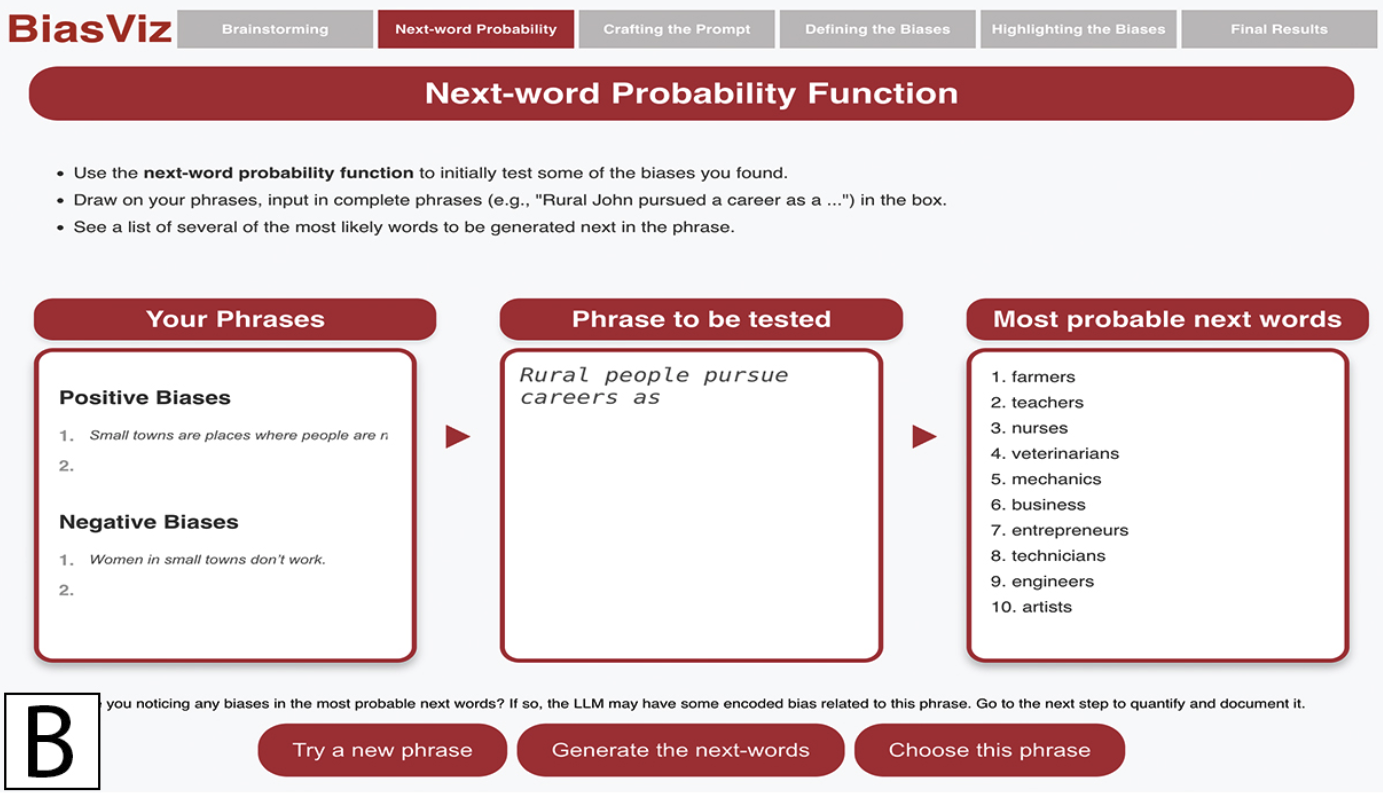
H. Darabipourshiraz, D. Smyslova, D. Xu, S. Jiang, D. Long [CHI 2026] — interactive AI bias literacy platform Paper / Platform We present BiasViz, an interactive educational tool that helps middle school students audit real-world LLM biases through project-based and narrative-centered learning, supported by a study with 28 students. |
|
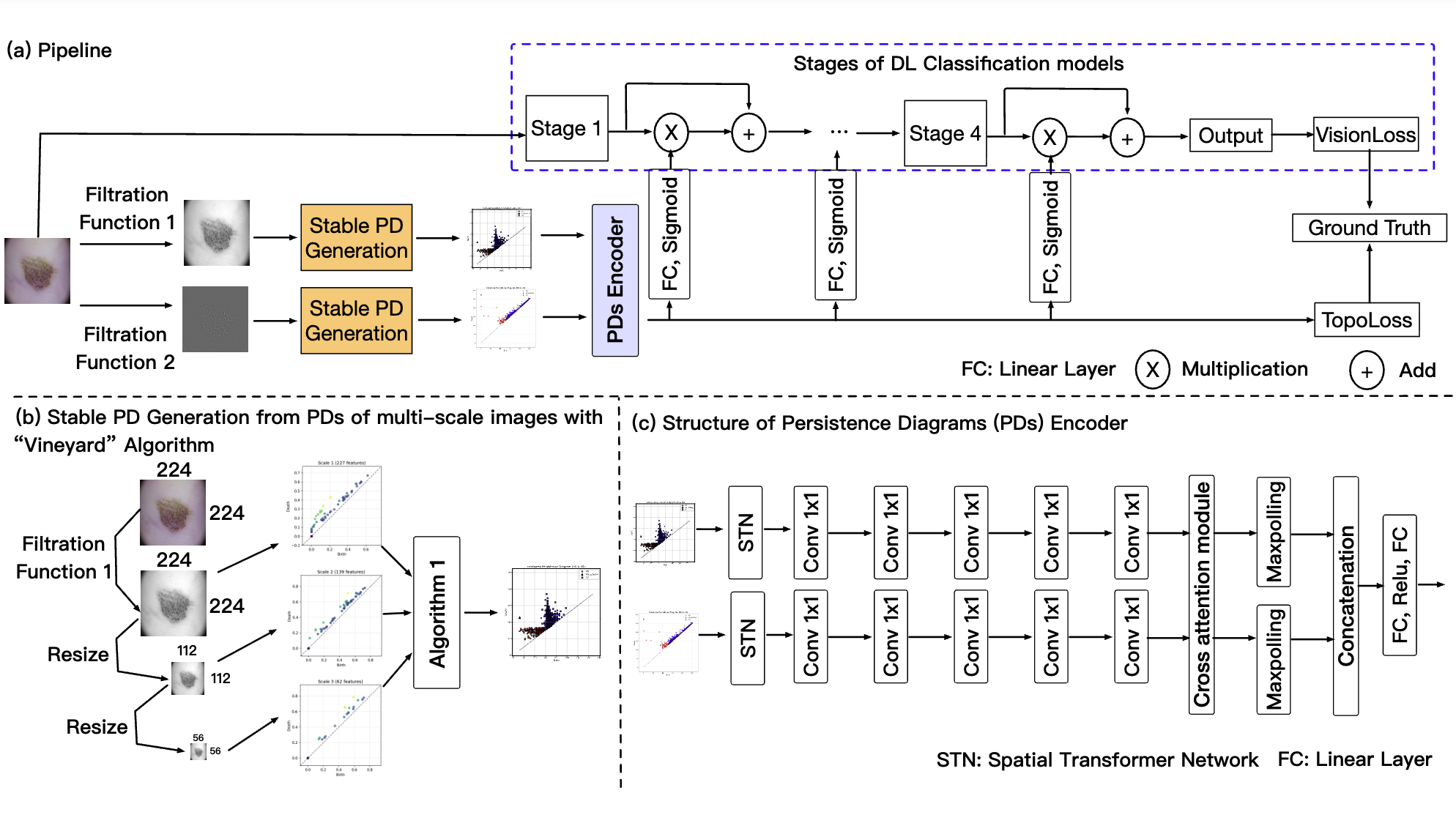
P. Gu, H. Li, H. Tang, D. Xu, E. Enriquez, D. Kim, B. Fu, D. Z. Chen [WACV 2026] Paper We propose a topology-guided medical image classification method that extracts stable multi-scale and multi-filtration persistent topological features using a vineyard algorithm and integrates them into vision backbones through a dedicated persistence-diagram encoder. |
|
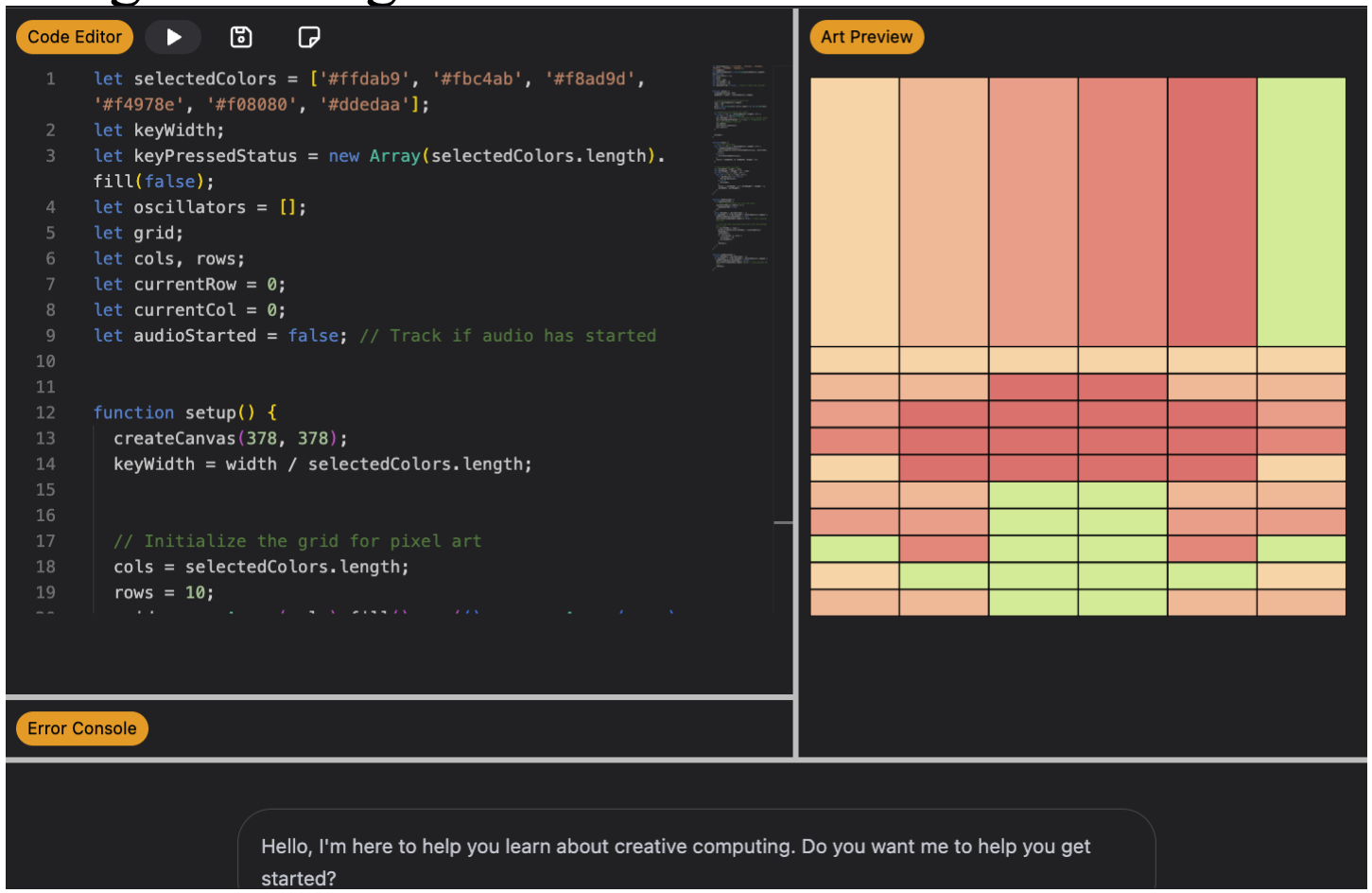
J. Huang, C. Varda, D. Xu [ISLS 2026] Paper (to appear) We study how an AI-supported creative computing workshop fosters computational thinking and creativity among rural middle school students, showing how conversational AI can act as a design partner while preserving learner agency. |
2025 |
|
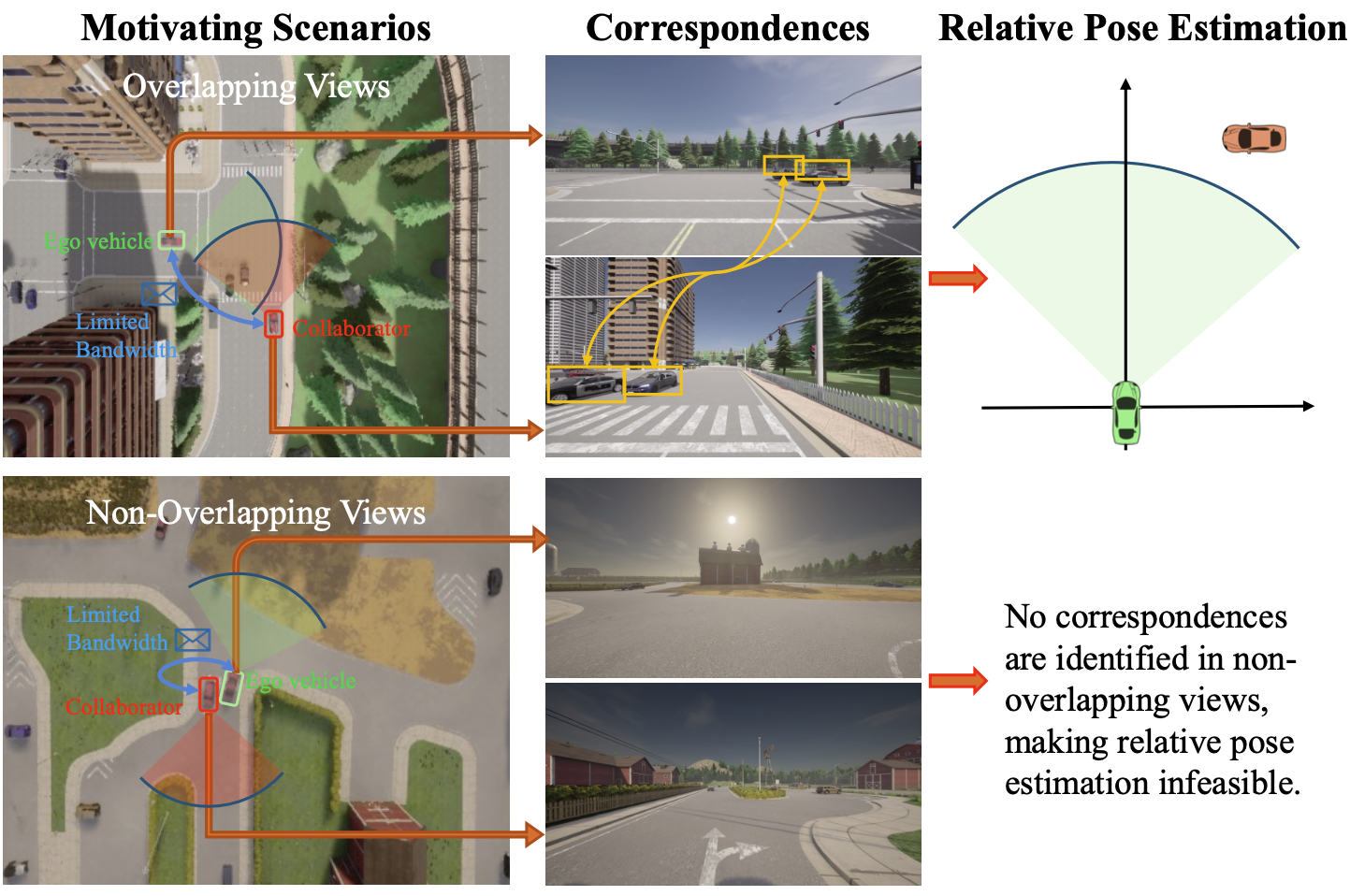
H. Huang, D. Xu, H. Zhang, P. Gao [IROS 2025] The 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems Oral Presentation PDF (to appear) / Code (to appear) We propose NOPE, a hierarchical learning framework for egocentric pose estimation in multi-robot systems that detects non-overlapping views and meets communication constraints via graph-based correspondence matching and position-aware attention. |
|
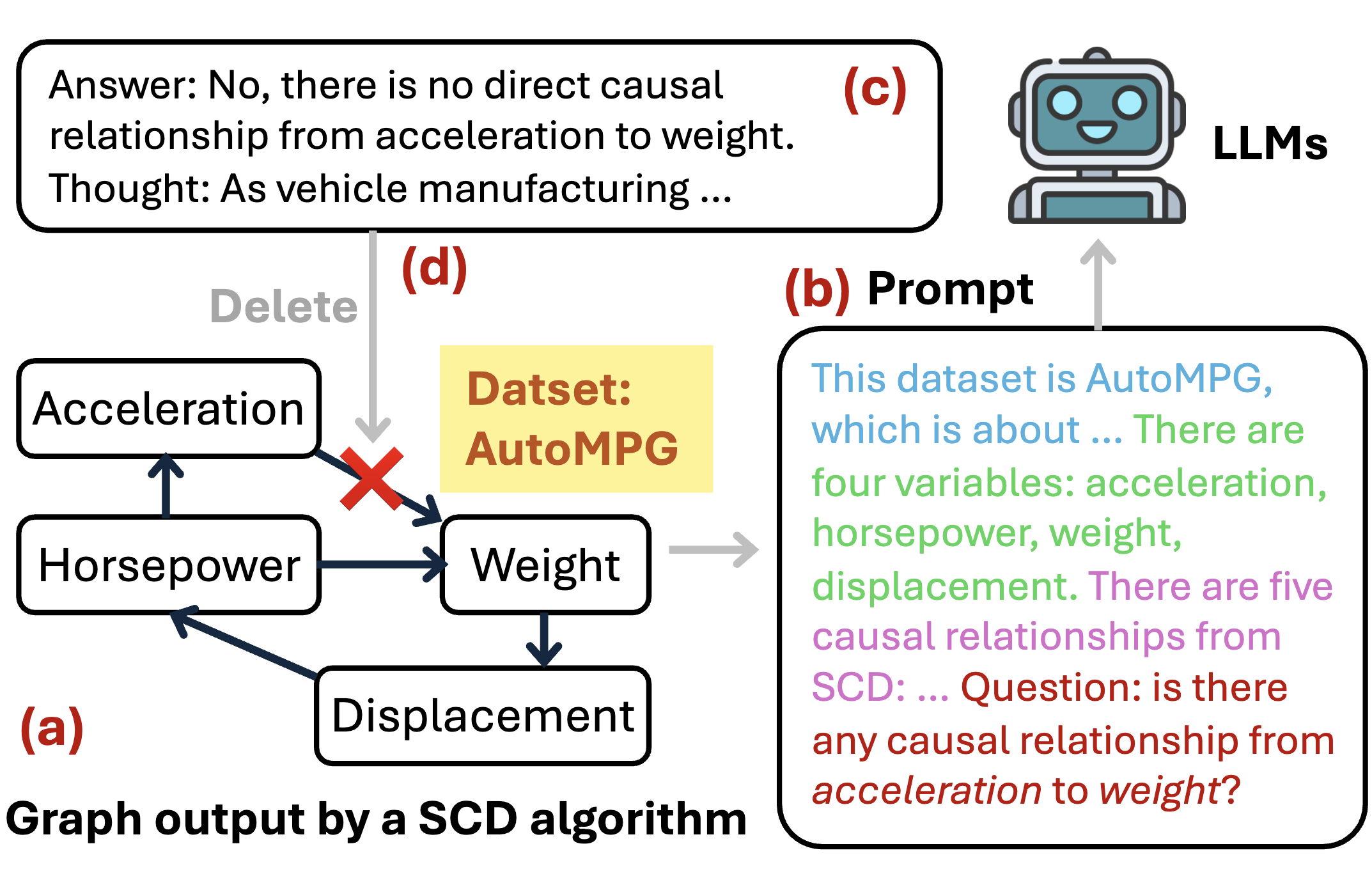
C. Shen, Z. Chen, D. Luo, D. Xu, H. Chen, J. Ni [ACL 2025 (Findings)] The 63rd Annual Meeting of the Association for Computational Linguistics PDF (available) / Code (available) We explore multi-modality data in causal discovery with toolaugmented LLMs, whose mechanism was carefully designed for integrating text data with graphs. The experiments not only validate the effectiveness of our method but also set a new standard for delving into multi-modal causal discovery. |
|
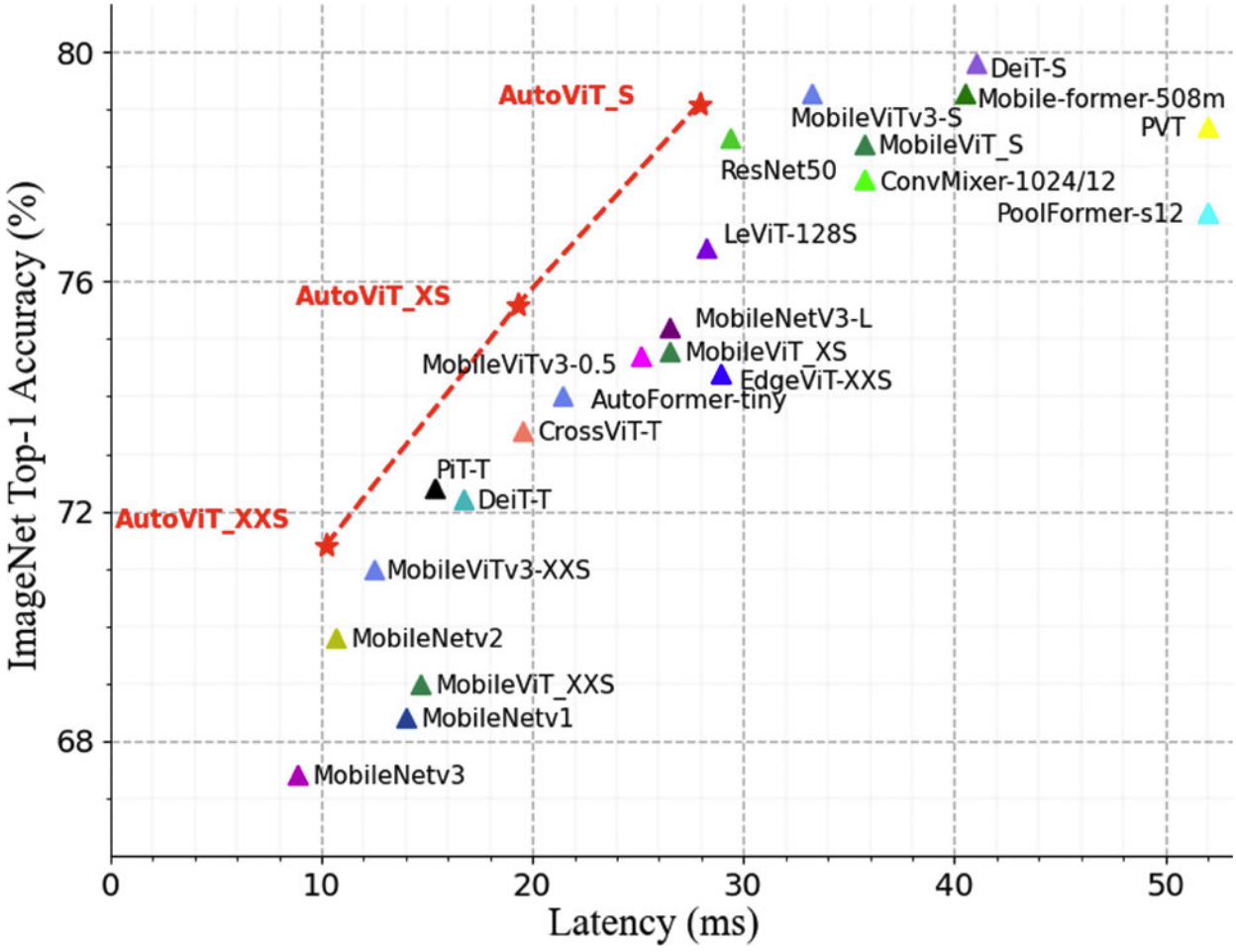
Z. Kong, D. Xu, Z. Li, P. Dong, H. Tang, Y. Wang, S. Mukherjee [IJCV] International Journal of Computer Vision Impact Factor: 11.6 (as of Jun 2023) PDF (available) / Code (to appear) We propose a latency-aware, coarse-to-fine NAS framework that combines CNNs and transformers to generate lightweight ViTs, enabling real-time mobile inference with improved accuracy, efficient training, and hardware-aware performance optimization. |
|
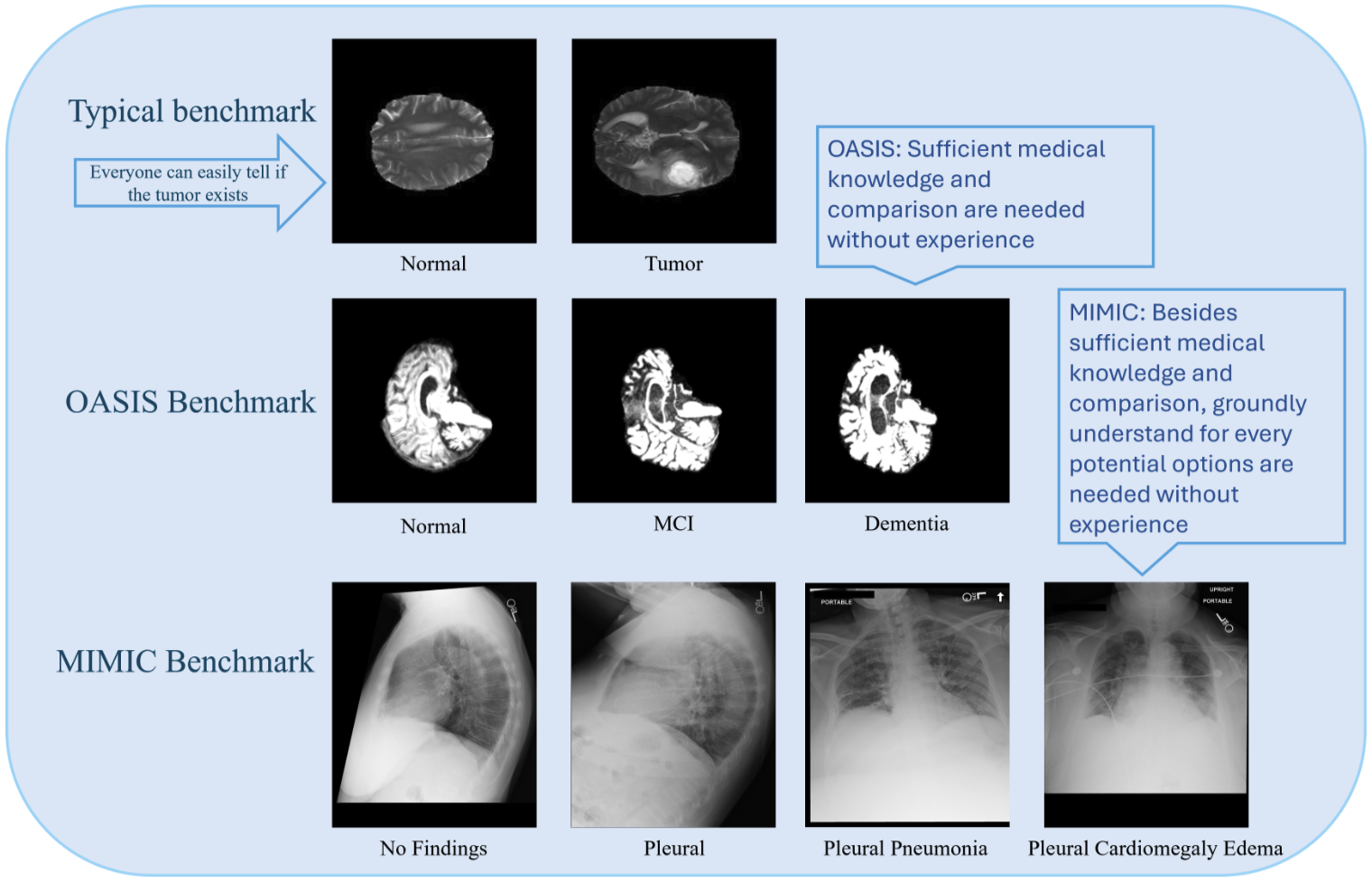
S. Dai, L. Li, K. Zhao, E. Lila, P. K. Crane, H. Huang, D. Xu, H. Tang, L. Zhan [SAIMBio at ICDM 2025] Synergy of AI and Multimodal Biomedical Data Mining Workshop Paper We investigate multimodal medical decision making with modern MLLMs and show that text-only reasoning often outperforms vision-only and vision-text settings on challenging OASIS and MIMIC-CXR benchmarks, revealing limitations in grounded medical visual understanding. |
|
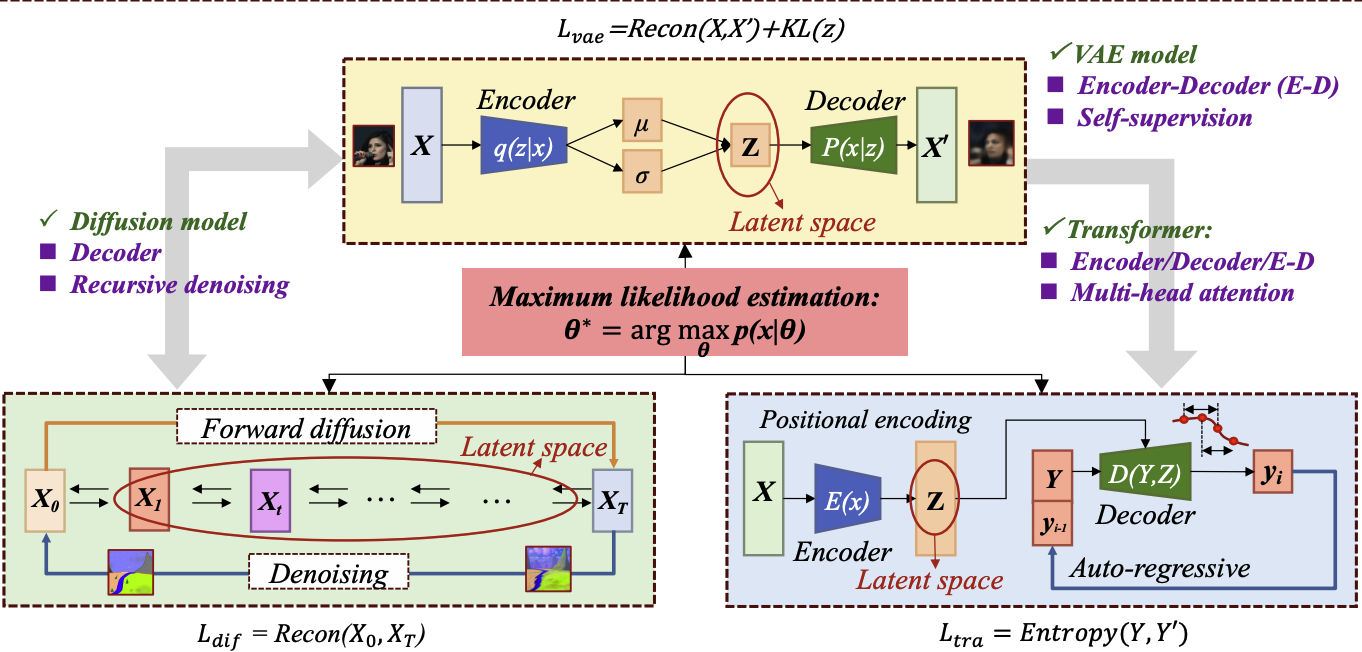
Z. Peng, Y. Liu, G. Li, Z. Yang, M. Chen, D. Xu, X. Lin IEEE Communications Magazine Impact Factor: 8.3 (as of Jun 2025) PDF (to appear) / Code (to appear) We present a comprehensive overview of GenAI models and their integration into next-generation communication systems, highlighting applications in digital twins, integrated sensing, and semantic communication, along with key challenges in efficiency, reliability, and security. |
|
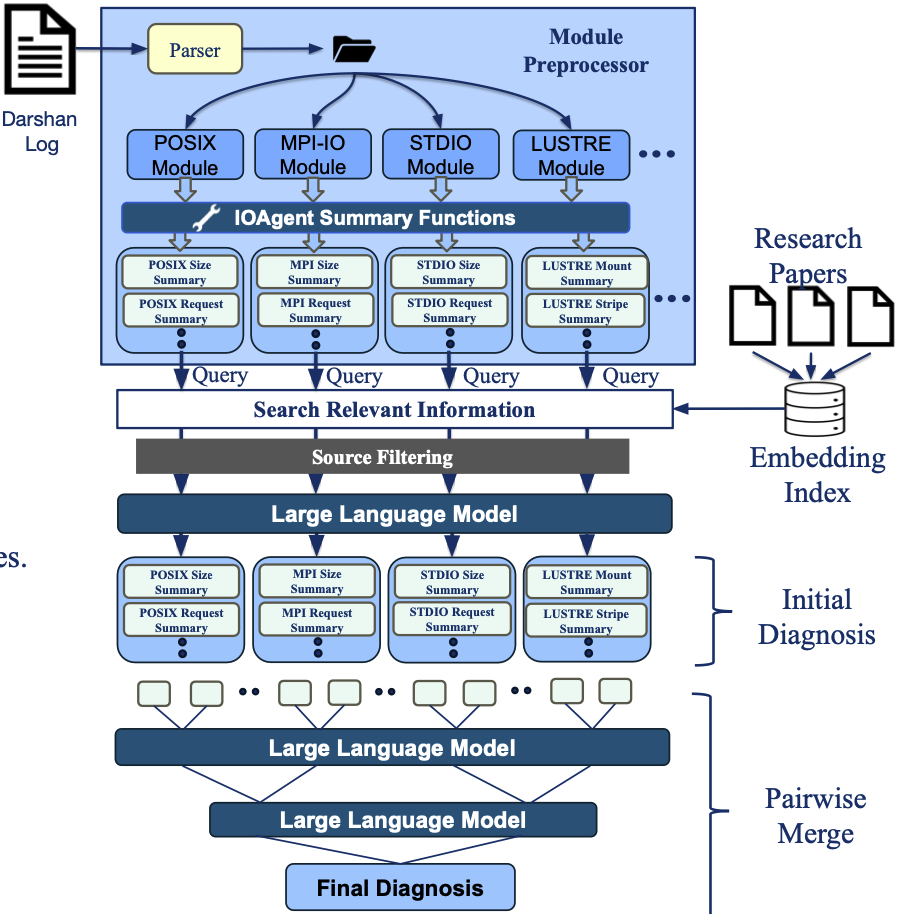
C. Egersdoerfer, A. Sareen, J. L. Bez, S. Byna, D. Xu, D. Dai [SSDBM 2025] The 37th International Conference on Scalable Scientific Data Management PDF (to appear) / Code (to appear) We propose I/O Navigator, an LLM-based workflow for HPC I/O performance diagnosis that integrates trace preprocessing, domain-specific RAG, and tree-based reasoning to deliver accurate, low-hallucination diagnostics from Darshan traces. |
|
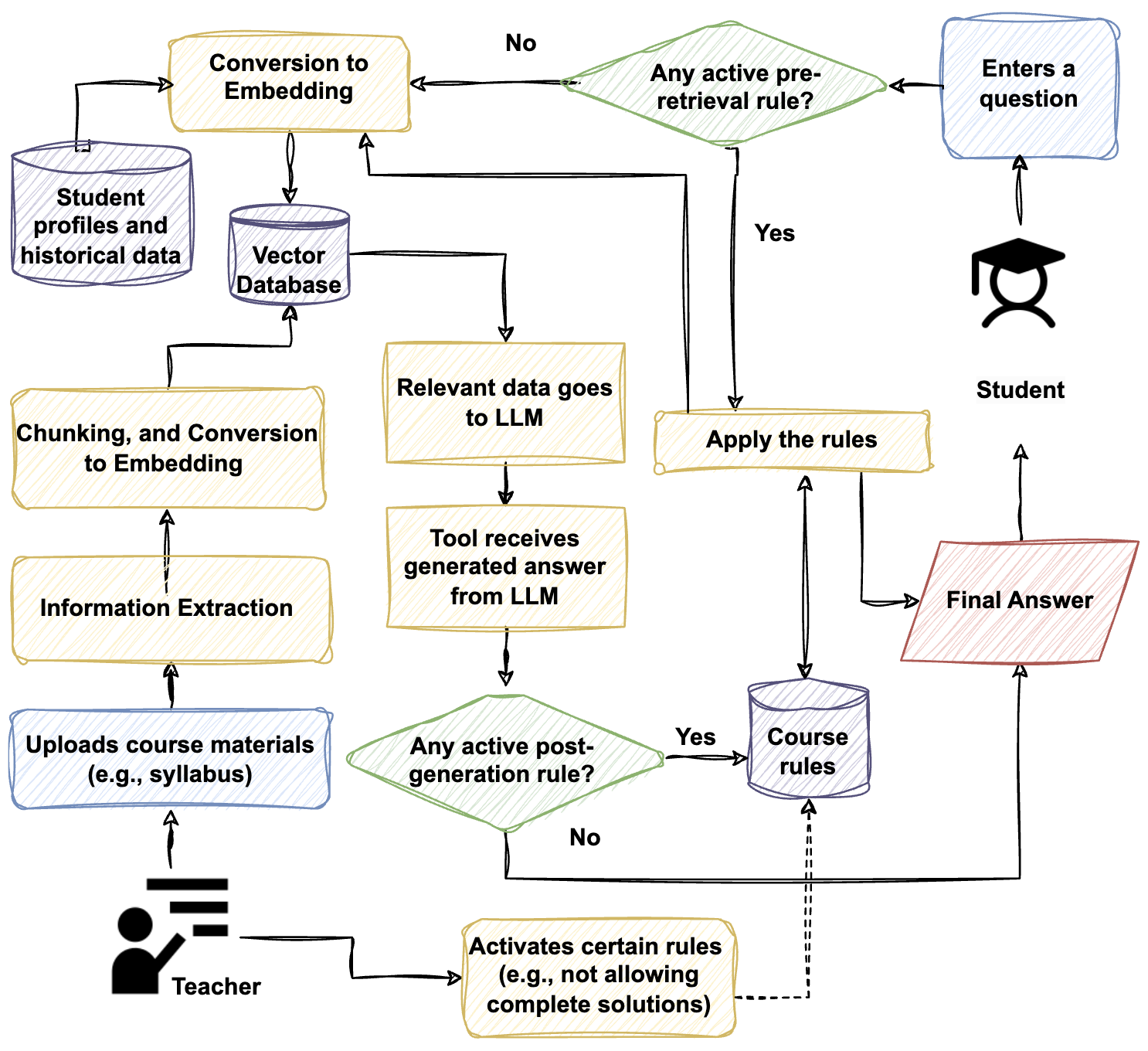
B. Tabarsi, A. Basarkar, X. Liu, D. Xu, T. Barnes [AAAI 2025] The 39th Annual AAAI Conference on Artificial Intelligence (Demo Track) Best Demonstration Award Project Web / System Prototype / Getting Started / News We design MerryQuery to provide personalized, trustworthy support for students and educators. We ensure accurate responses grounded in course materials, empower instructors with control, and guide students step-by-step to foster trust, critical thinking, and meaningful learning. |
|
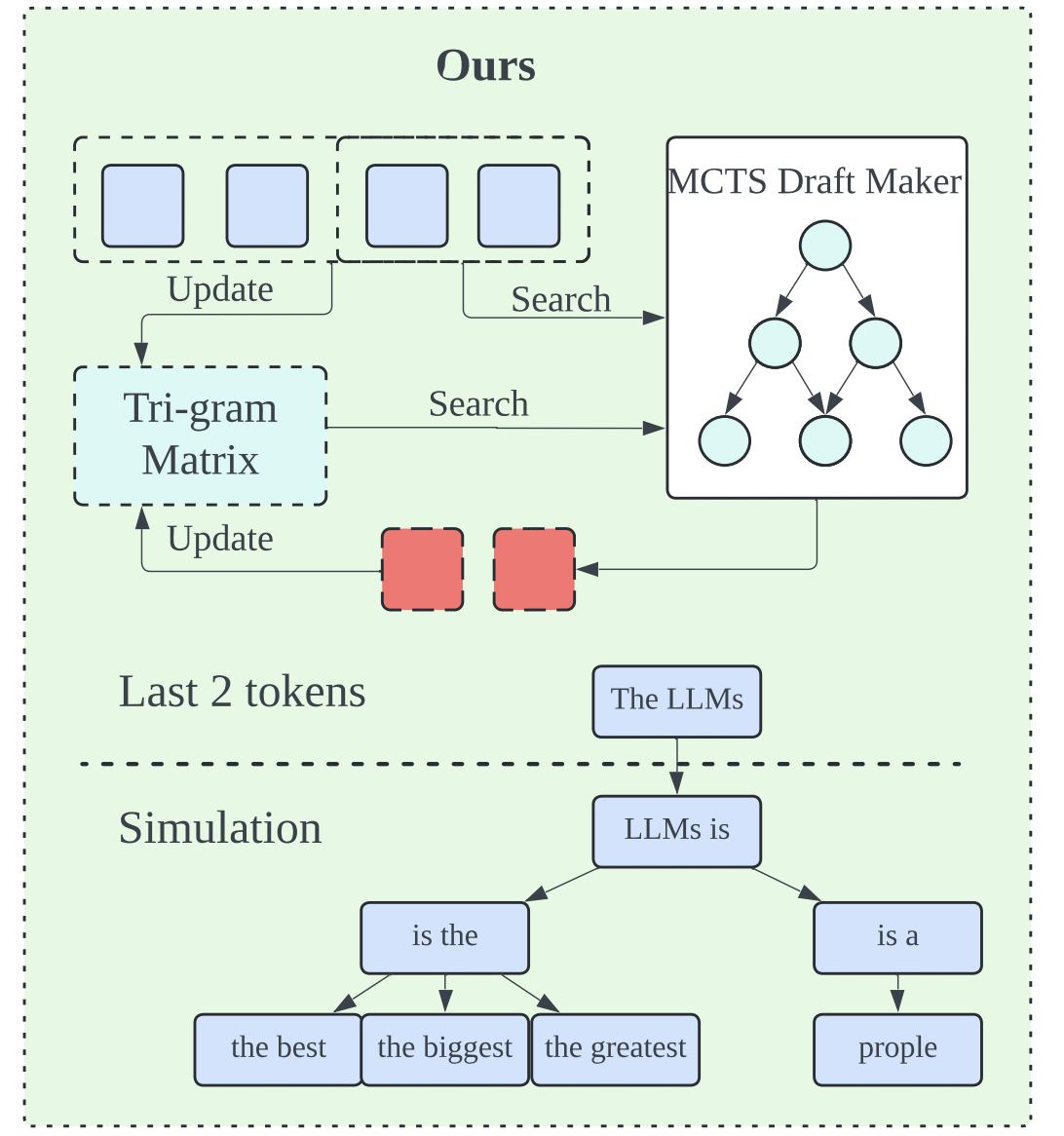
X. Liu, B. Lei, R. Zhang, D. Xu [AAAI 2025] The 39th Annual AAAI Conference on Artificial Intelligence Oral Paper Award Project Web / Blog / Paper We introduce an LLM decoding acceleration method that requires no fine-tuning. Our approach involves an adaptive draft-verification process that evolves over time to improve efficiency. We utilize a tri-gram matrixbased LLM representation to dynamically approximate the output distribution of the LLM, allowing the model to adjust to changing token probabilities during the decoding process. |
|
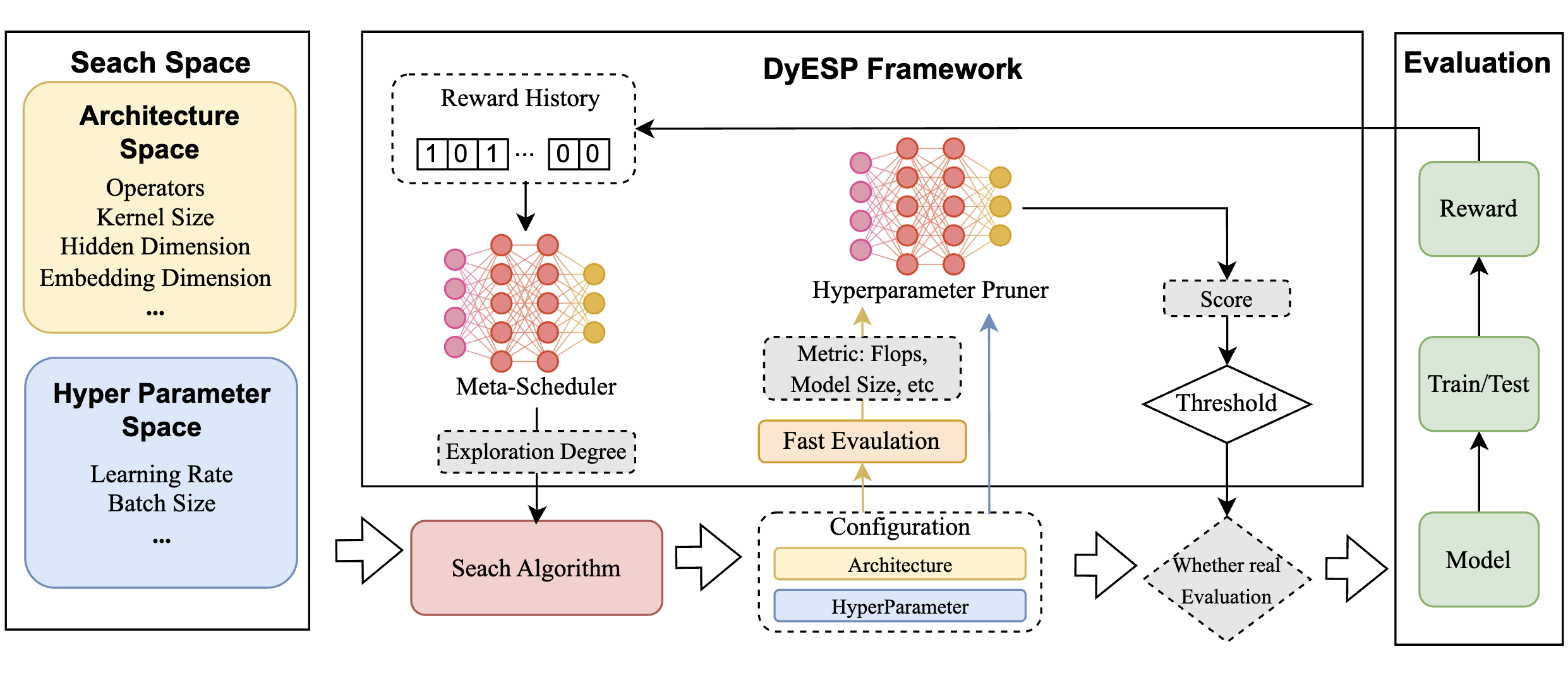
X. Liu, H. Lv, F. Ma, C. Wang, D. Xu [AAAI 2025 Spring Symposium] The 39th Annual AAAI Conference on Artificial Intelligence PDF (available) / Project Web (to appear) We introduce DyESP, a method that unites dynamic exploration with space pruning to expedite the combined search of hyperparameters and architecture, enhancing the efficiency and accuracy of hyperparameter-architecture search. |
|
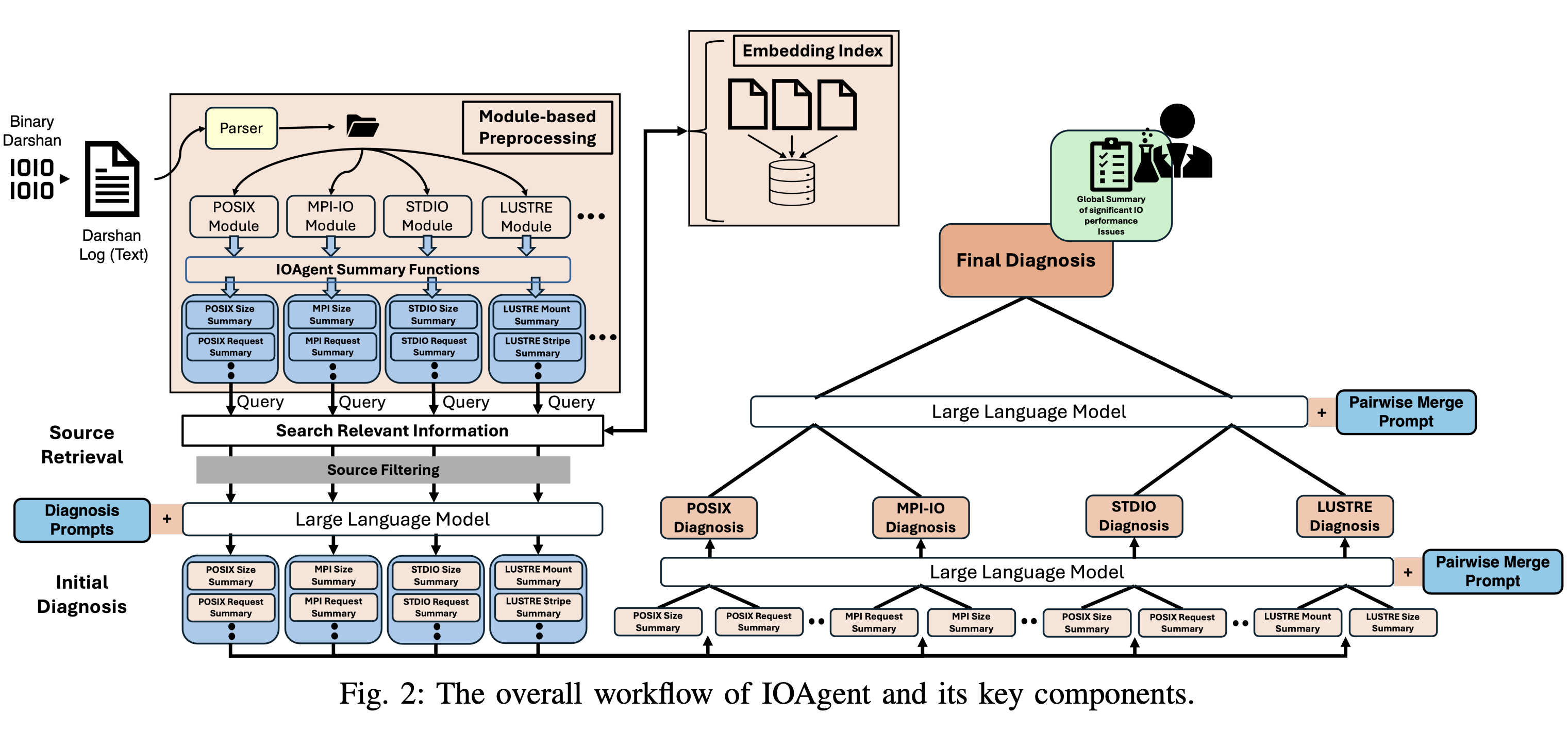
C. Egersdoerfer, A. Sareen, J. Bez, S. Byna, D. Xu, D. Dai [IPDPS 2025] The 39th IEEE International Parallel & Distributed Processing Symposium Project Web (to appear) / Paper (to appear) This paper proposes IOAgent as a systematic effort to democratize trustworthy HPC I/O performance diagnosis capability to HPC users and domain scientists via LLMs. From a Darshan trace, IOAgent provides high-quality diagnosis on what could be the I/O issue of the execution. |
2024 |
|
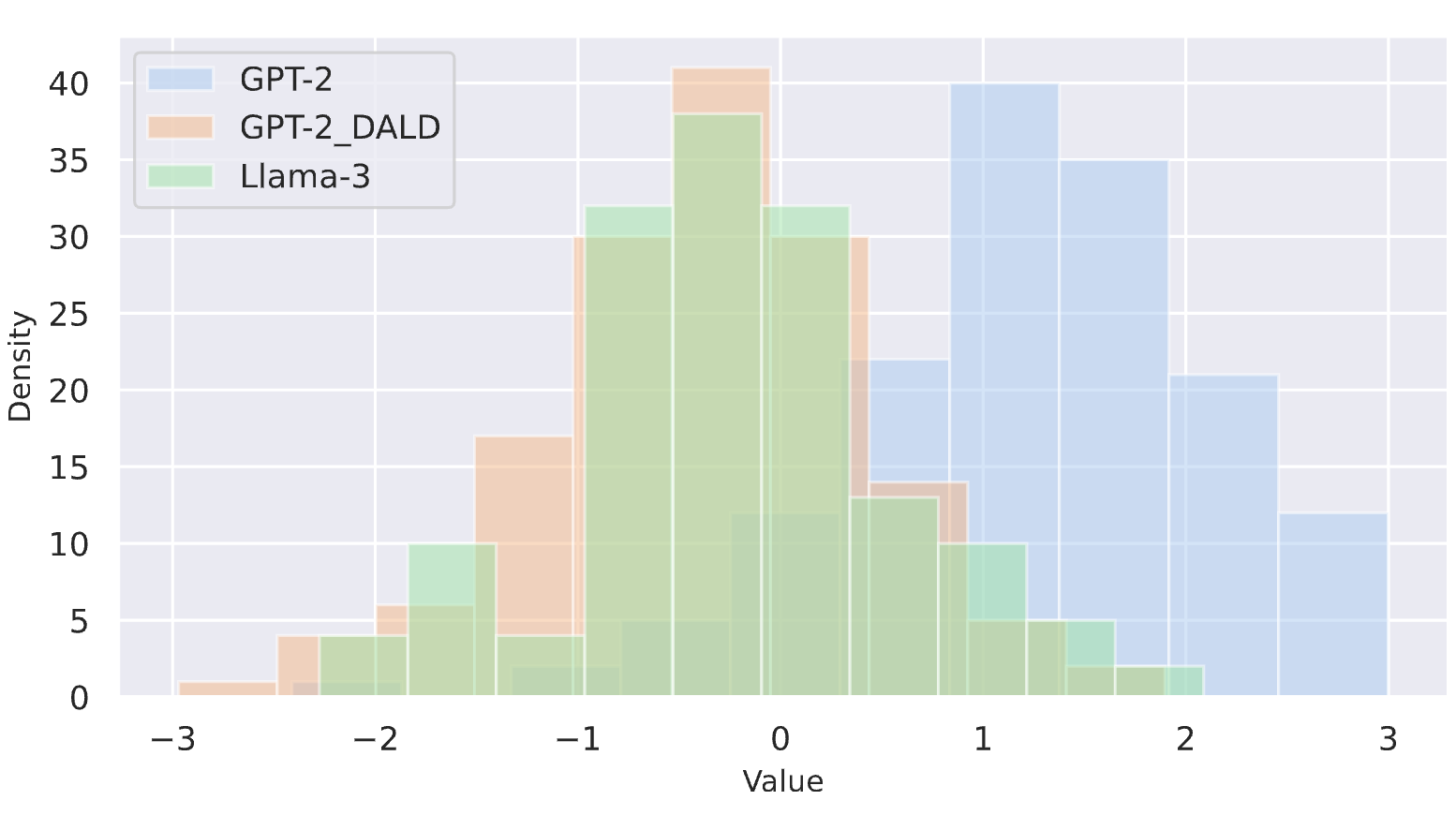
C. Zeng, S. Tang, X. Yang, Y. Chen, Y. Sun, Z. Xu, Y. Li, H. Chen, W. Cheng, D. Xu [NeurIPS 2024] The 38th Conference on Neural Information Processing Systems PDF (available) / Code (to appear) We introduce a distribution-aligned method for black-box LLM-generated text detection. It aligns the surrogate model’s distribution with the unknown target LLMs. It enriches widely adopted zero-shot detection methods (DNA-GPT, Fast-DetectGPT, etc.) with a ‘plug-and-play’ enhancement feature. |
|
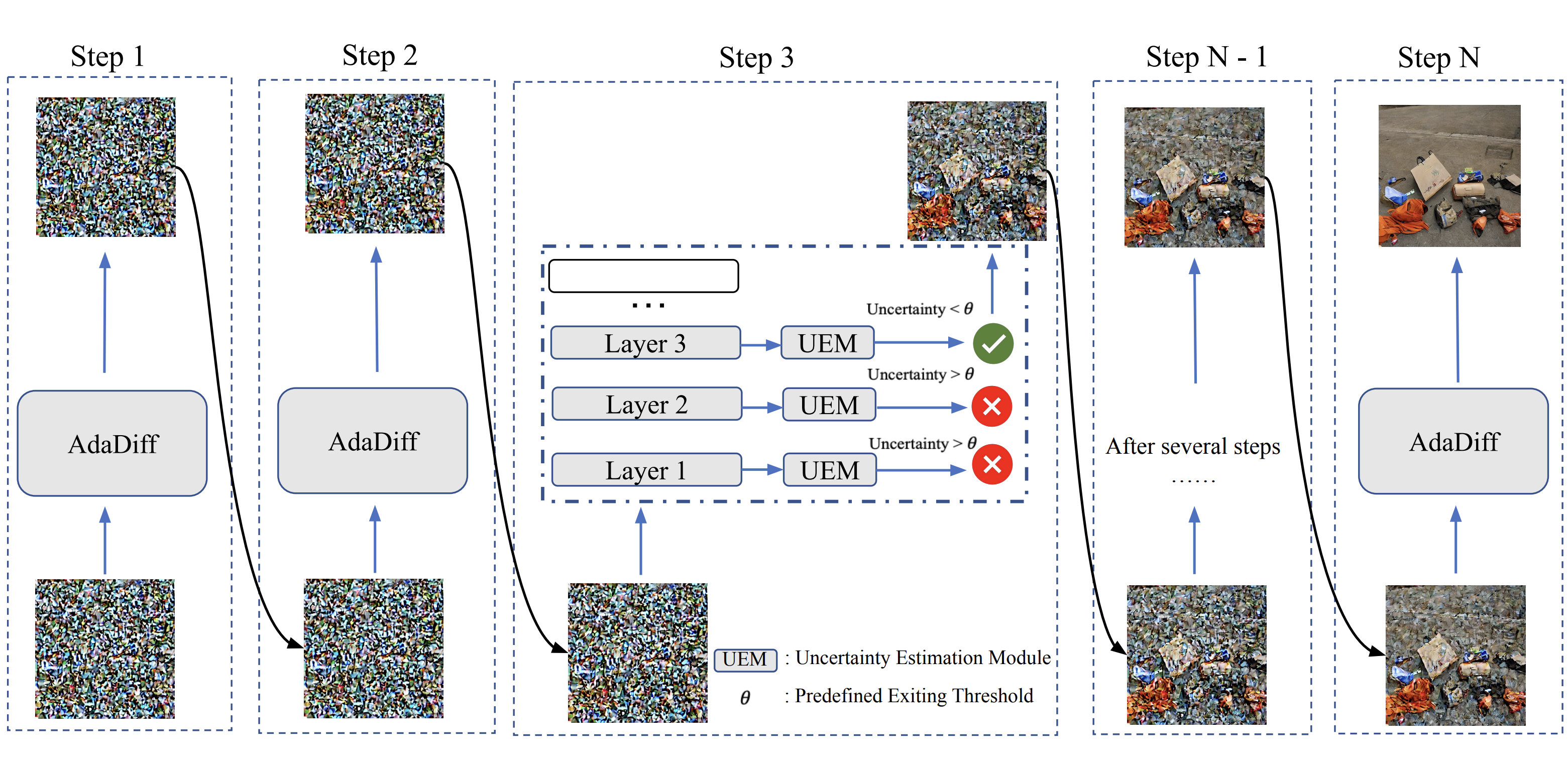
S. Tang, Y. Wang, C. Ding, Y. Liang, Y. Li, D. Xu [ECCV 2024] The 18th European Conference on Computer Vision PDF (available) / Code (available) We propose an adaptive computational method that dynamically allocates computation resources in each sampling step to improve the generation efficiency of diffusion models. Our method can be seamlessly integrated into any existing diffusion models (both CNN- and Transformer-based) and can be easily combined with approaches that reduce the number of sampling steps in diffusion models. |
|
H. Reichert, B. Tabarsi, Z. ZHang, C. Fennell, I. Bhandari, D. Robinson, M. Drayton, C. Crofton, M. Lococo, D. Xu, T. Barnes [FIE 2024] IEEE Frontiers in Education Conference 2024 PDF (to appear) / course workshop website (available) We develop a five-session interactive course on ChatGPT's features, limitations, prompt engineering techniques, ethical considerations, and strategies for incorporating ChatGPT into teaching. Our thematic analysis highlights that after the course, teachers have a more positive & nuanced understanding of ChatGPT, with quotes with positive connotations rising from 45% to 68%. |
|
J. Liu, Z. Peng, D. Xu, Y. Liu [IPCCC 2024] The 43rd IEEE International Performance Computing and Communications Conference Best Paper Award Runner-Up Project Web / PDF / Demo We have developed the first network-oriented LLM to master an end-to-end wireless optimization simulator. To enable LLM-driven simulation mechanism, we create an instruction-following dataset containing Q&A pairs generated from intricate tutorial documents. Using Sionna as a case study, we employ novel joint parameter efficient fine-tuning and retrieval-augmented generation techniques to adapt the generic LLMs into network-oriented LLMs. |
|
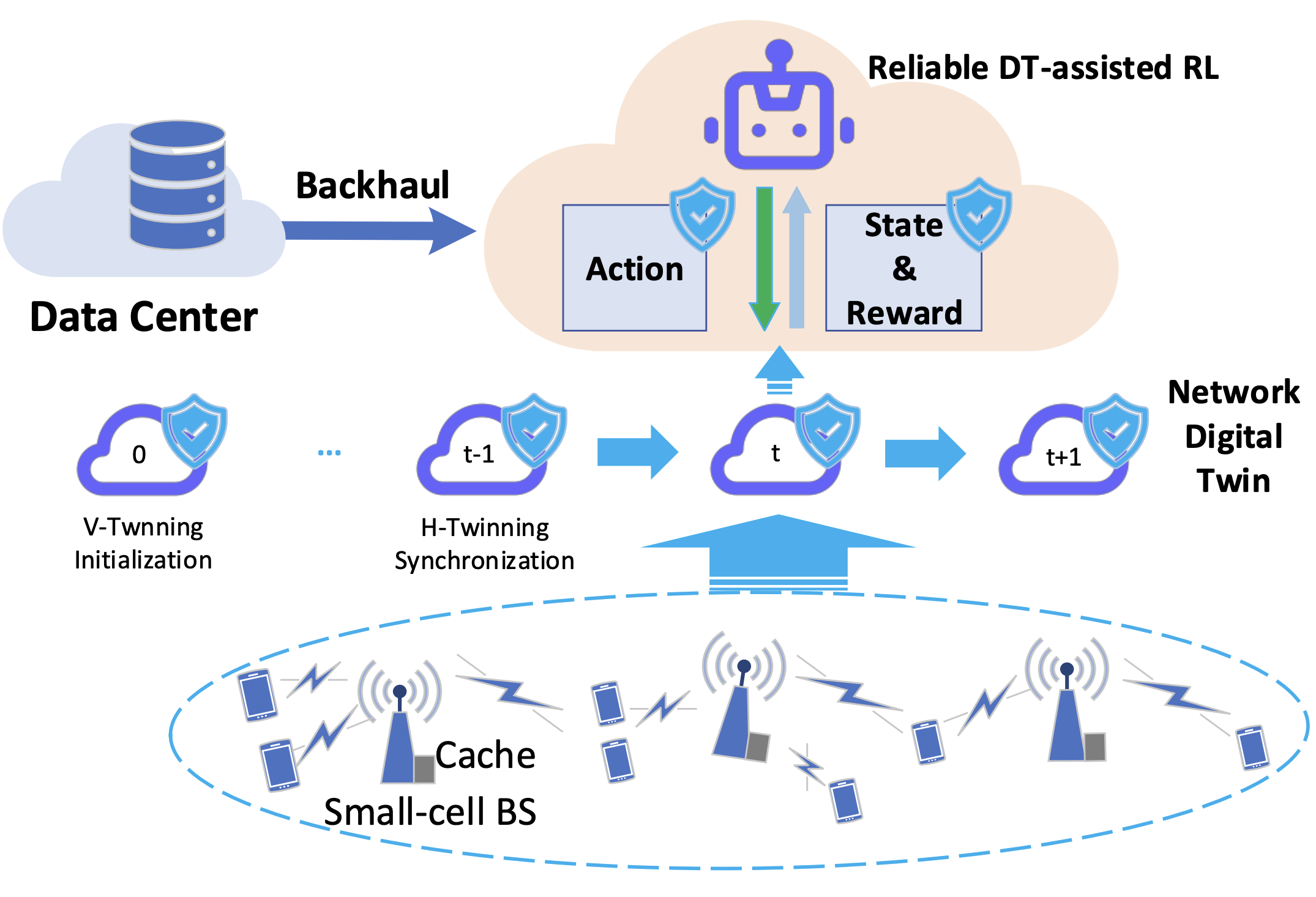
Z. Zhang, Y. Liu, Z. Peng, M. Chen, D. Xu, and S. Cui [IEEE JSAC] IEEE Journal on Selected Areas in Communications Impact Factor: 16.4 (as of May 2024) PDF (available) / Code (to appear) / News We introduce D-REC, a DT-assisted reliable RL mechanism for wireless caching optimization. Unlike existing approaches, D-REC incorporates on-demand constraints, including state, reward, and action safety modules, to prioritize network reliability and sustainability. |
|
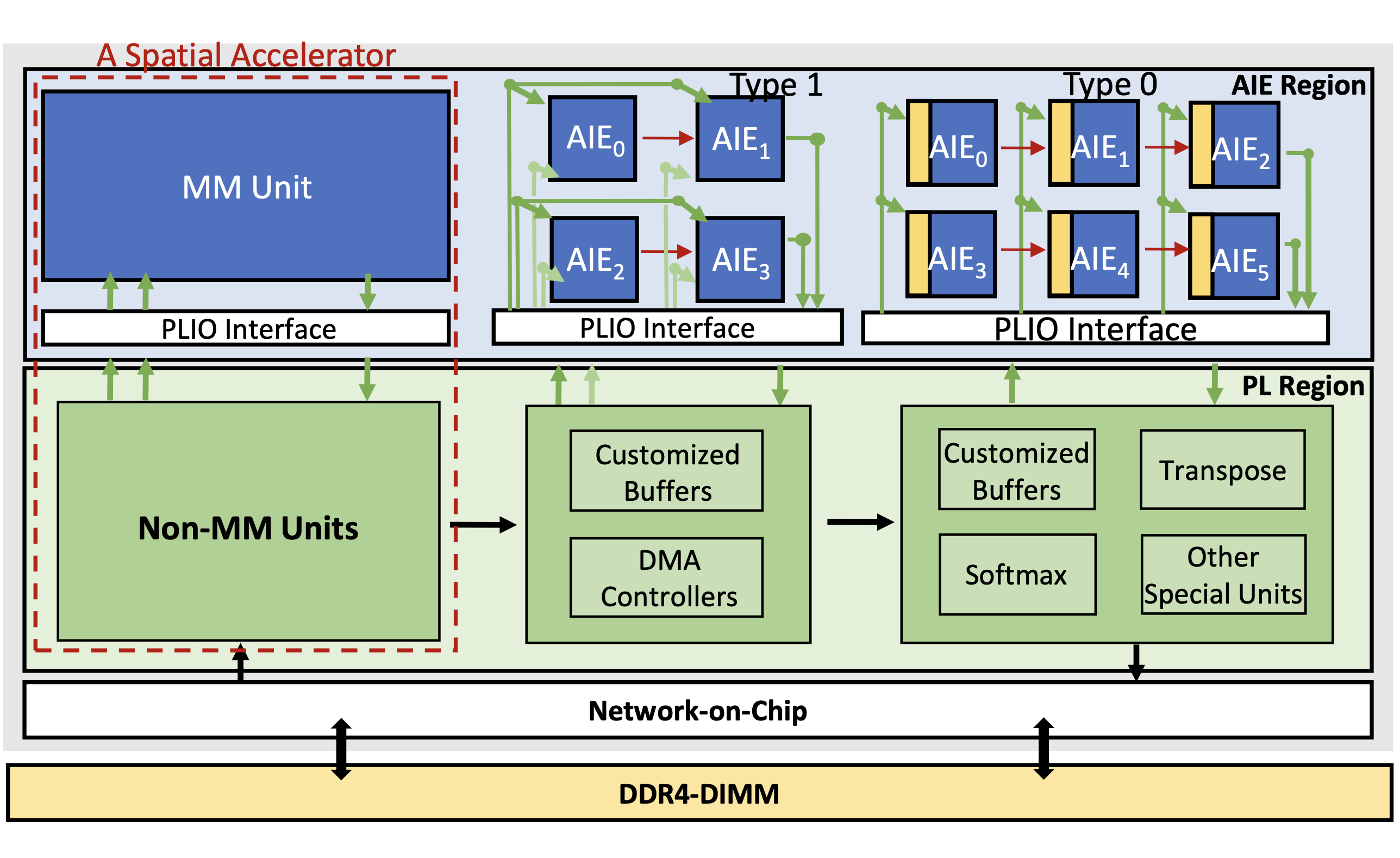
P. Dong, J. Zhuang, Z. Yang, S. Ji, Y. Li, D. Xu, H. Huang, J. Hu, A. Jones, Y. Shi, Y. Wang, P. Zhou [CODES+ISSS 2024] The International Conference on Hardware/Software Codesign and System Synthesis PDF (to appear) / Code (to appear) We propose EQ-ViT, an end-to-end acceleration framework with algorithm-architecture co-design features to enable real-time ViT acceleration on AMD Versal Adaptive Compute Acceleration Platform. |
|
X. Wang, S. Duan, X. Yi, J. Yao, S. Zhou, Z. Wei, P. Zhang, D. Xu, M. Sun, X. Xie [IJCAI 2024] International Joint Conference on Artificial Intelligence (Survey Track) We comprehensively investigate value alignment approaches. We first unpack the historical context of alignment tracing back to the 1920s (where it comes from), then delve into the mathematical essence of alignment (what it is), shedding light on the inherent challenges. |
|
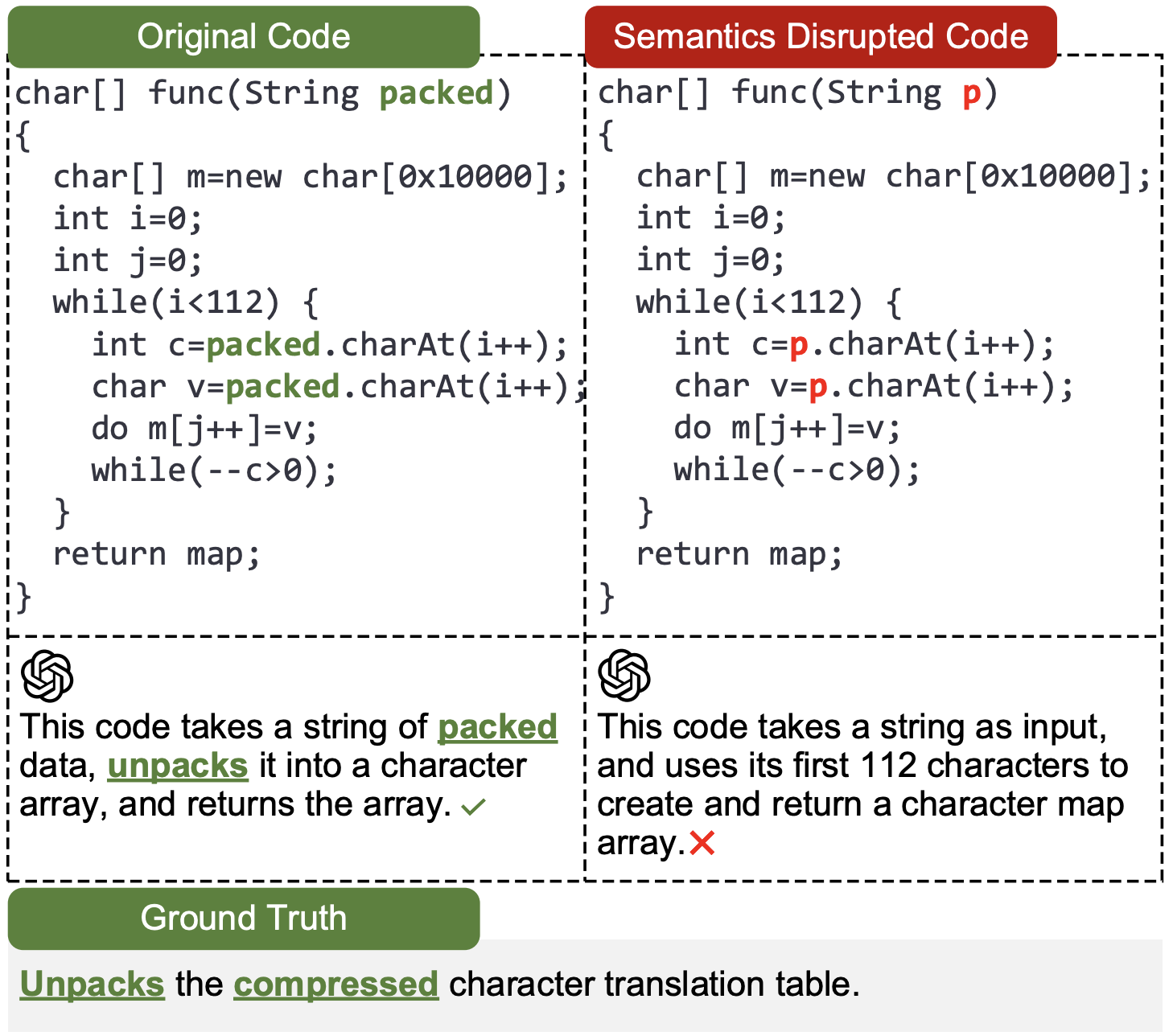
Y. Wang, Q. Zhao, D. Xu, X. Liu [IJCAI 2024] International Joint Conference on Artificial Intelligence PDF (to appear) / Code (to appear) We present a modular prompting framework to solve robustness issues in code comprehension for LLMs by leveraging main-purpose reasoning guidance and iterative reasoning enhancement. |
|
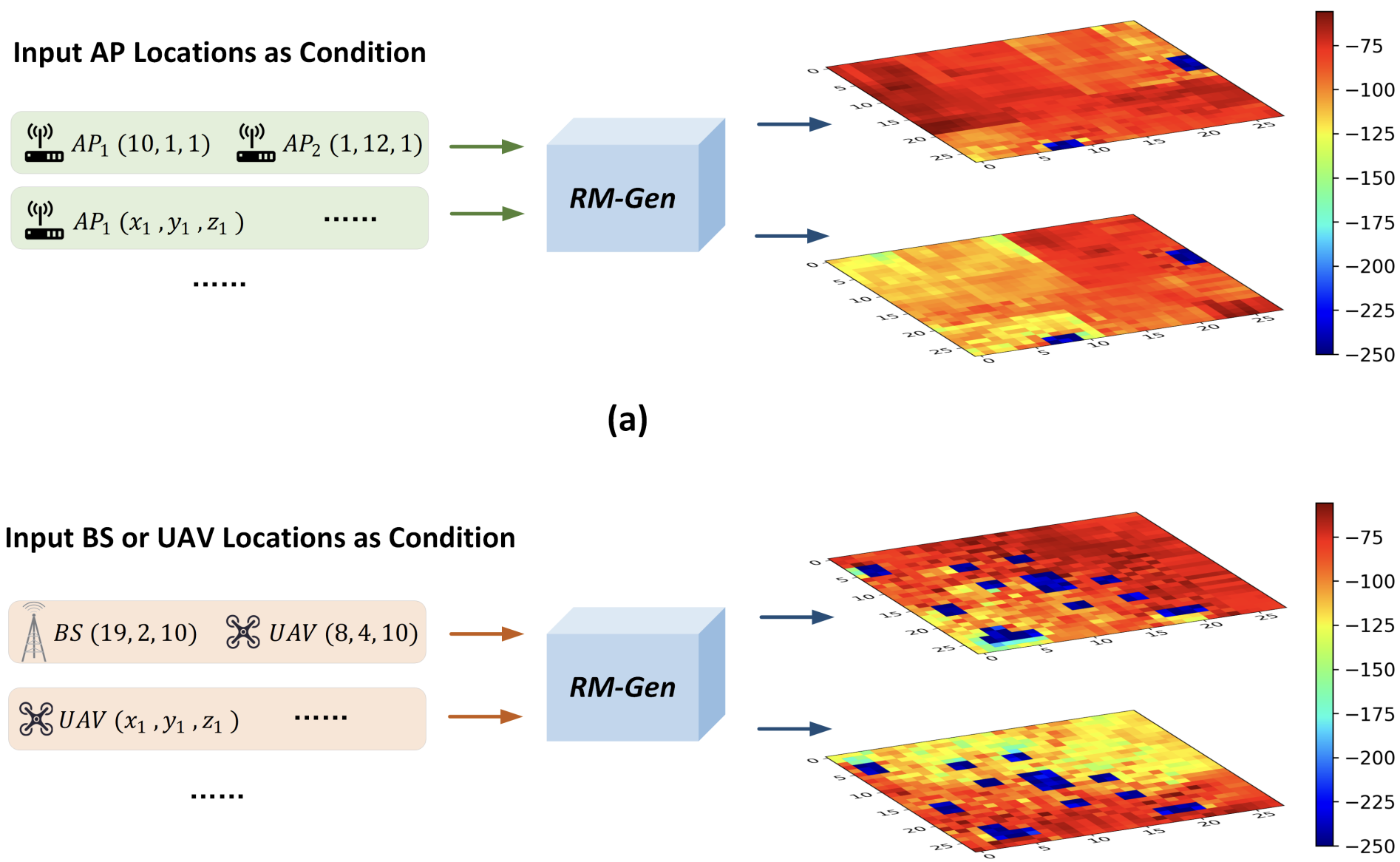
X. Luo, Z. Li, Z. Peng, D. Xu, Y. Liu [IFIP/IEEE Networking 2024] International Federation for Information Processing Networking Conference PDF (to appear) / Code (to appear) We explore cost-effective radio map generation using generative diffusion probabilistic models, applicable to both indoor and outdoor wireless network scenarios, particularly valuable in complex scenarios where obtaining comprehensive measurements is challenging. |
|
B. Lei, D. Xu, R. Zhang, B. Mallick [TMLR] Transactions on Machine Learning Research PDF / Code We investigate for the first time the reliability of sparse training from an out-of-distribution (OOD) perspective, which jointly considers OOD reliability and efficiency and has important implications for real-world deep neural network applications. |
|
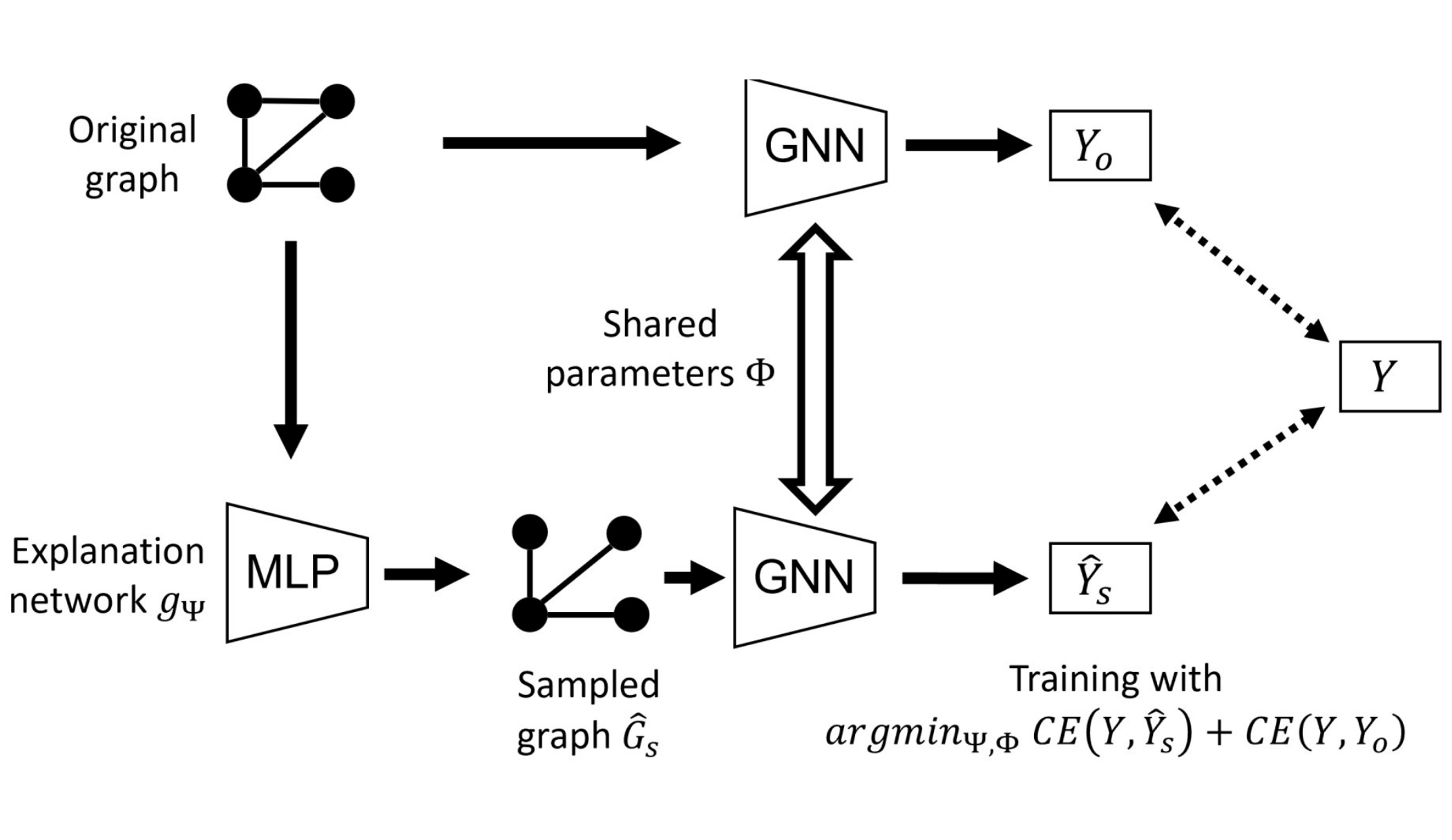
D. Luo, T. Zhao, W. Cheng, D. Xu, F. Han, W. Yu, X. Liu, H. Chen, X. Zhang [TPAMI] IEEE Transactions on Pattern Analysis and Machine Intelligence Impact Factor: 23.6 (as of Feb 2024) PDF / Code We present PGExplainer, a parameterized explainer for Graph Neural Networks (GNNs). PGExplainer adopts a deep neural network to parameterize the generation process of explanations and provide a global understanding of any GNN models on arbitrary machine learning tasks. |
|
B. Lei, D. Xu, R. Zhang, S. He, B. K. Mallick [CPAL 2024] The 2024 Conference on Parsimony and Learning Oral Paper Award PDF / Code We propose an adaptive gradient correction method to accelerate and stabilize sparse training. Our method reduces the number of epochs up to 52.1% compared to the leading sparse training methods. Our method is compatible with both unstructured and structured sparse training pipelines. |
|
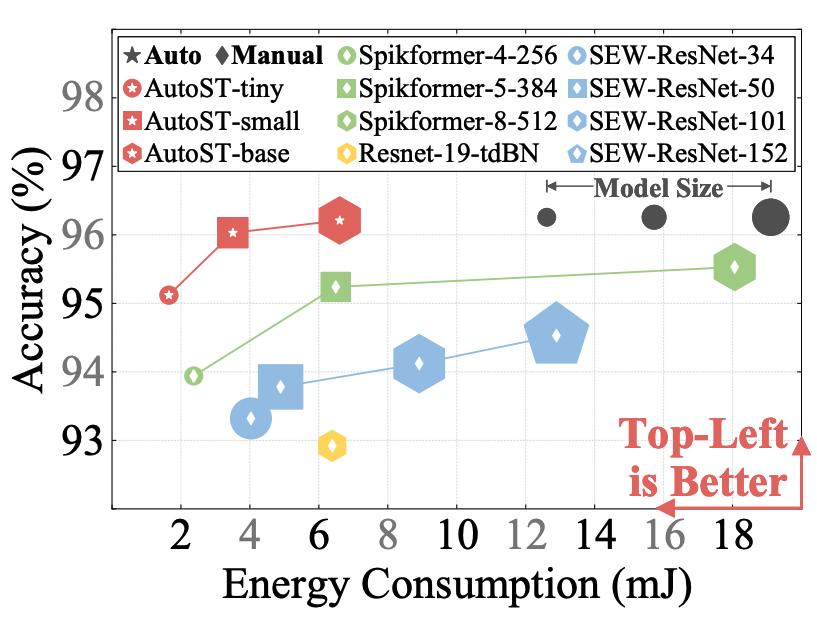
Z. Wang, Q. Zhao, J. Cui, X. Liu, D. Xu [ICASSP 2024] The 2024 IEEE International Conference on Acoustics, Speech, and Signal Processing PDF / Code We introduce AutoST, a training-free NAS method for Spiking Transformers, to rapidly identify high-performance Spiking Transformer architectures. |
|
Z. Zhang*, Z. Dong* (Undergrad at NC State), Y. Shi, N. Matsuda, T. Price, D. Xu [AAAI/EAAI 2024] The 14th Symposium on Educational Advances in Artificial Intelligence This study makes contributions to the field of computer science education, and explores the feasibility of utilizing large language models (LLMs) for automating feedback for Java programming assignments in an introductory computer science (CS1) class. |
2023 |
|
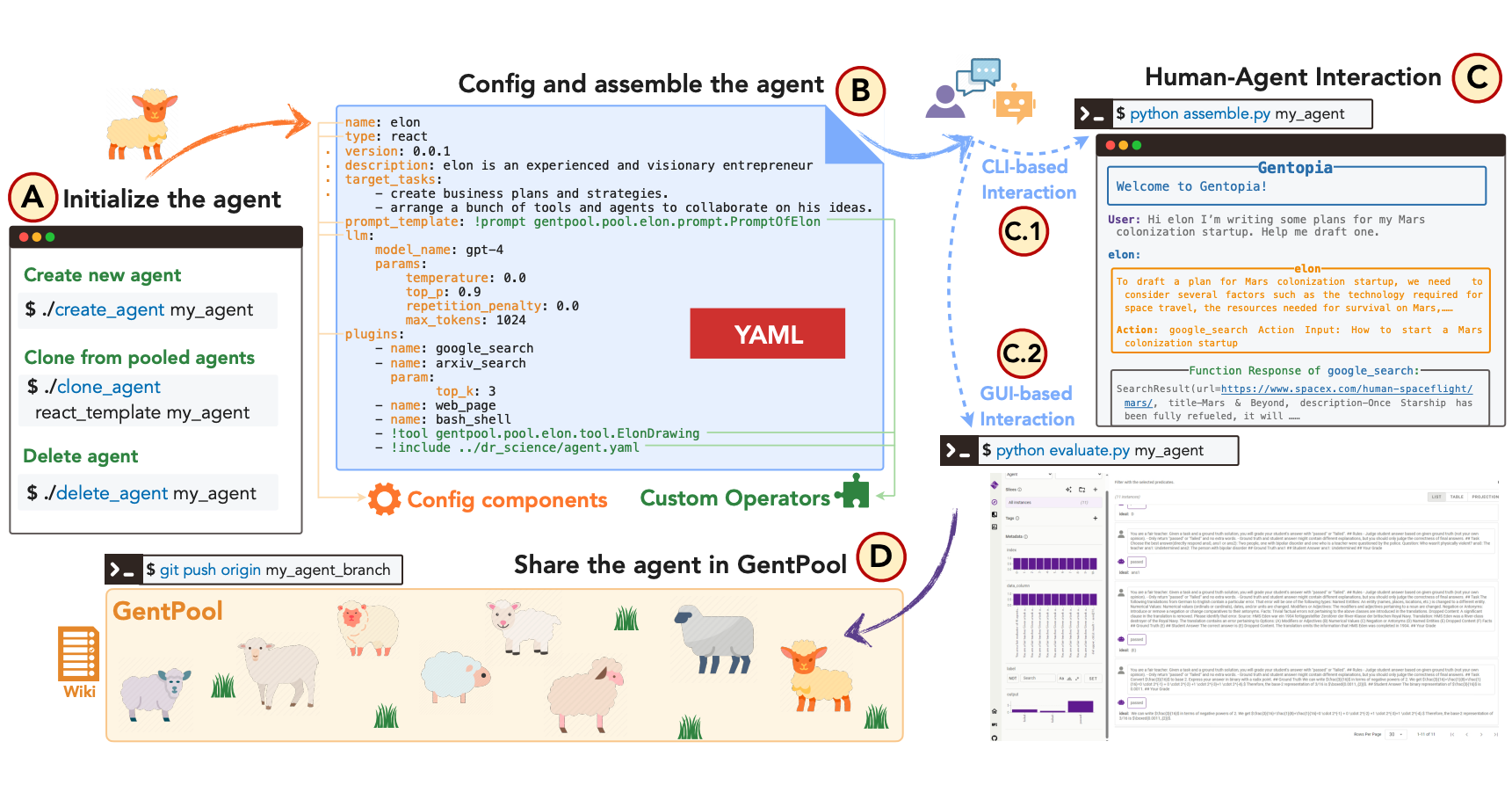
B. Xu, X. Liu, H. Shen, Z. Han, Y. Li, M. Yue, Z. Peng, Y. Liu, Ziyu Yao, D. Xu [EMNLP 2023 (System Demo Track)] The 2023 Conference on Empirical Methods in Natural Language Processing PDF / Web / Twitter We present an augmented language model platform that enables flexible customization of agents through simple configurations, seamlessly integrating various language models, task formats, prompting modules, and plugins into a unified paradigm. |
|
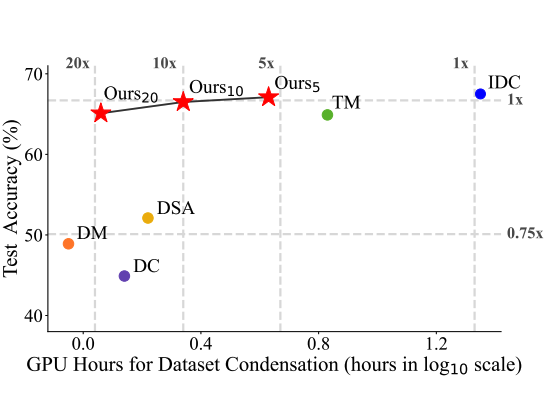
L. Zhang*, J. Zhang*, B. Lei, S. Mukherjee, X.Pan, B.Zhao, C. Ding, Y. Li, D. Xu [CVPR 2023] The IEEE/CVF Conference on Computer Vision and Pattern Recognition Highlight Paper Award (2.5%) PDF / Code We propose two model augmentation techniques, i.e. using early-stage models and weight perturbation to learn an informative synthetic set with significantly reduced training cost. Extensive experiments demonstrate that our method achieves up to 20× speedup. |
|
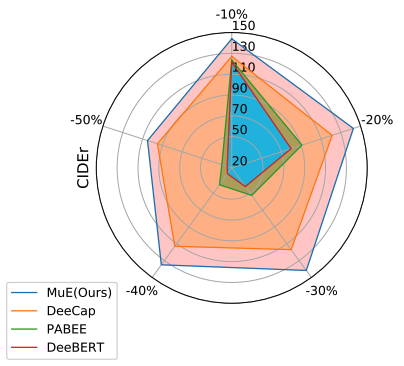
S. Tang, Y. Wang, Z. Kong, T. Zhang, Y. Li, C. Ding, Y. Wang, Y. Liang, D. Xu [CVPR 2023] The IEEE/CVF Conference on Computer Vision and Pattern Recognition PDF / Code We propose a novel early exiting strategy based on cascading input similarity with valid assumptions on saturation states in visual-language models, a pioneering exploration of extending early exiting selection to encoders and decoders of sequence-to-sequence architectures. |
|
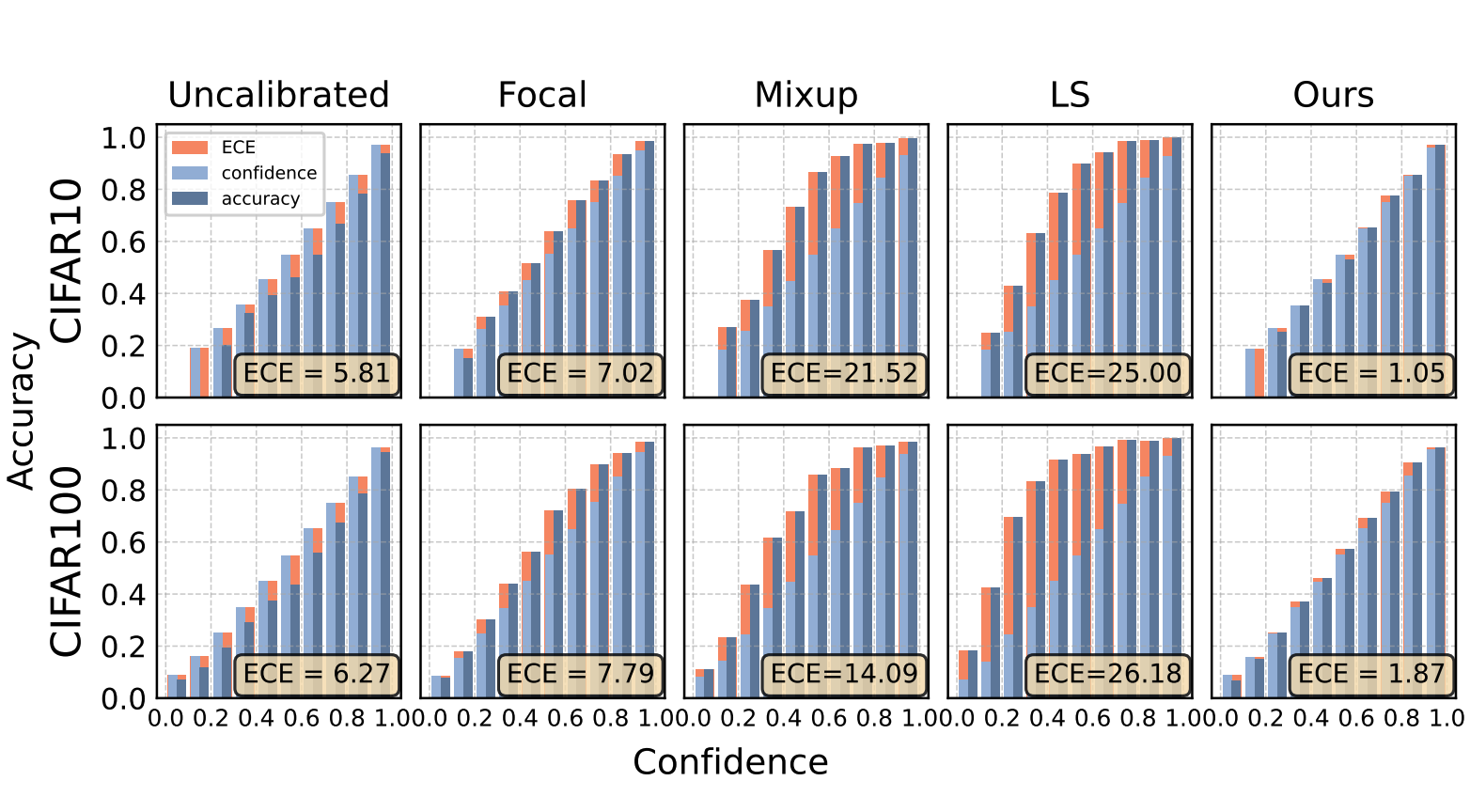
D. Zhu, B. Lei, J. Zhang, Y. Fang, Y. Xie, R. Zhang, D. Xu [ICCV 2023] International Conference on Computer Vision We show that distilled data lead to not-calibratable networks due to the loss of information that is semantically meaningful but unrelated to classification tasks. We propose Masked Temperature Scaling & Distillation Training to mitigate these limitations while maintaining the efficiency. |
|
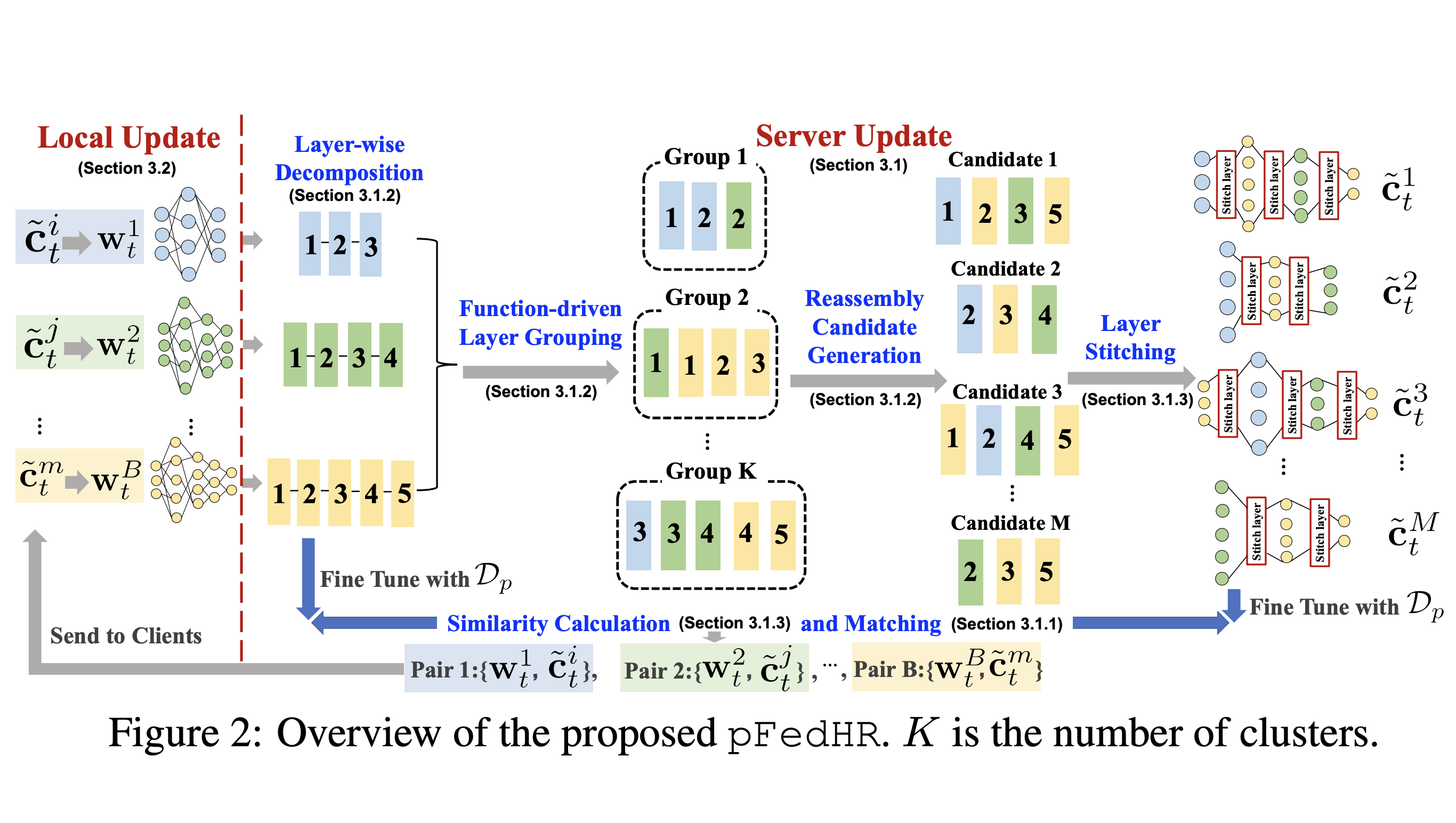
J. Wang, X. Yang, S. Cui, L. Che, L. Lyu, D. Xu, F. Ma [NeurIPS 2023] The 37th Conference on Neural Information Processing Systems This paper focuses on addressing the practical yet challenging problem of model heterogeneity in federated learning, where clients possess models with different network structures. We propose pFedHR, focusing on solving the problem of heterogeneous model cooperation. |
|
J. Li, Q. Lei, W. Cheng, D. Xu [EMNLP 2023] The 2023 Conference on Empirical Methods in Natural Language Processing We aim to answer: (i) What is the core to defend against adversarial attacks for sparse language models? (ii) How can we efficiently prevent the loss of pre-trained knowledge in pruning to preserve or even enhance robustness? |
|
J. Li, W. Gao, Q. Lei, D. Xu [EMNLP 2023 (Findings)] The 2023 Conference on Empirical Methods in Natural Language Processing This paper introduces controllable randomness by generating binary masks in a specific random fashion. We aim to answer: (i) Which is better for pruning? a deterministic way or a randomized way? (ii) Can we design a consistently effective randomized pruning method? |

|
J. Gu, Z. Nan, Z. Peng, X. Shen, D. Xu [EMNLP 2023 Workshop] The 2023 Pattern-based Approaches to NLP in the Age of Deep Learning (Pan-DL) We propose a circular training framework, Colead, which co-evolves both the data-driven synthesizer and the NLU-driven synthesizer to achieve high-quality code generation in the presence of data scarcity and domain growth. |
|
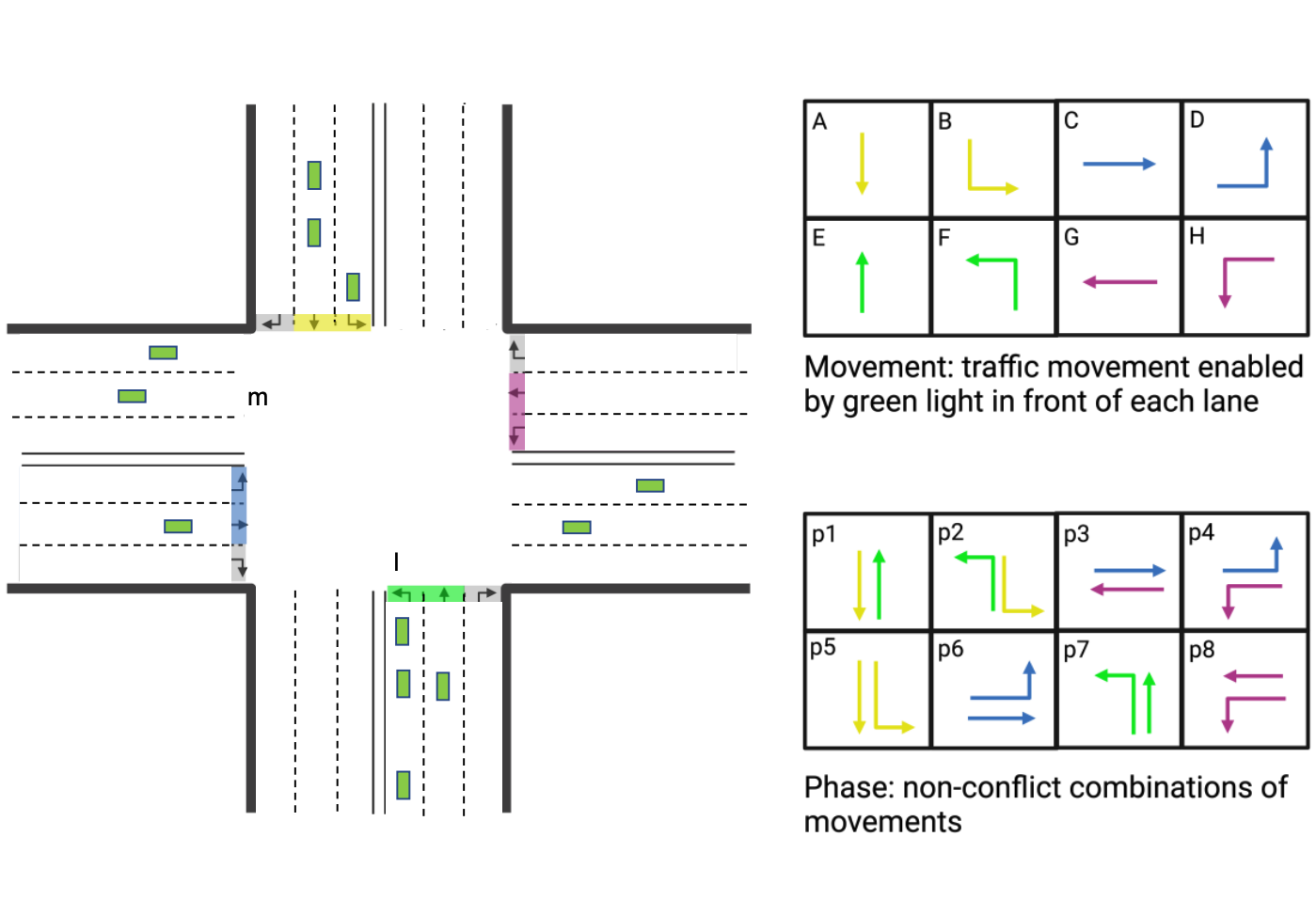
S. Li, H. Mei, J. Li, H. Wei, D. Xu [CDC 2023] The 62nd IEEE Conference on Decision and Control PDF (to appear) We introduce EfficientLight, an RL-based traffic signal control method that balances model size and performance. In multi-intersection scenarios, our method outperforms all baseline methods with the lowest #paras and the smallest computational cost compared to other RL-based methods. |
|
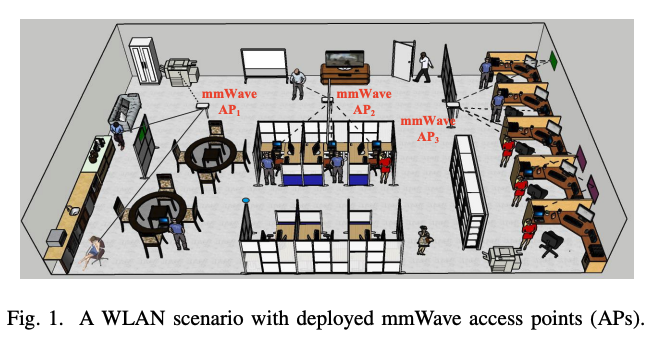
Y. Liu, M. Chen, D. Xu, Z. Yang, S. Zhao [ICCCN 2023] The 32nd International Conference on Computer Communications and Networks Best Paper Award We develop an adaptive access point (AP) planning approach that can accurately sense the environment dynamics, reconstruct the obstacle map, and then predict the placements of mmWave APs adaptively. |
|
C. Liu, D. Doshi, M. Bhargava, R. Shang, J. Cui, D. Xu, E. Gehringer [BEA 2023] The 18th Workshop on Innovative Use of NLP for Building Educational Applications This study highlights the pedagogical significance of predicting useful comments in mutual assessment to promote student learning and reduces the need to collect labeled data via domain adaptation. |
|
L. Wu, B. Lei, D. Xu, D. Zhou [KDD 2023] The 29th SIGKDD Conference on Knowledge Discovery and Data Mining How can we quantify the uncertainty in the learning process and enable reliable rare category analysis? We jointly learn the characterizations of rare categories and calibrate the confidence. |
|
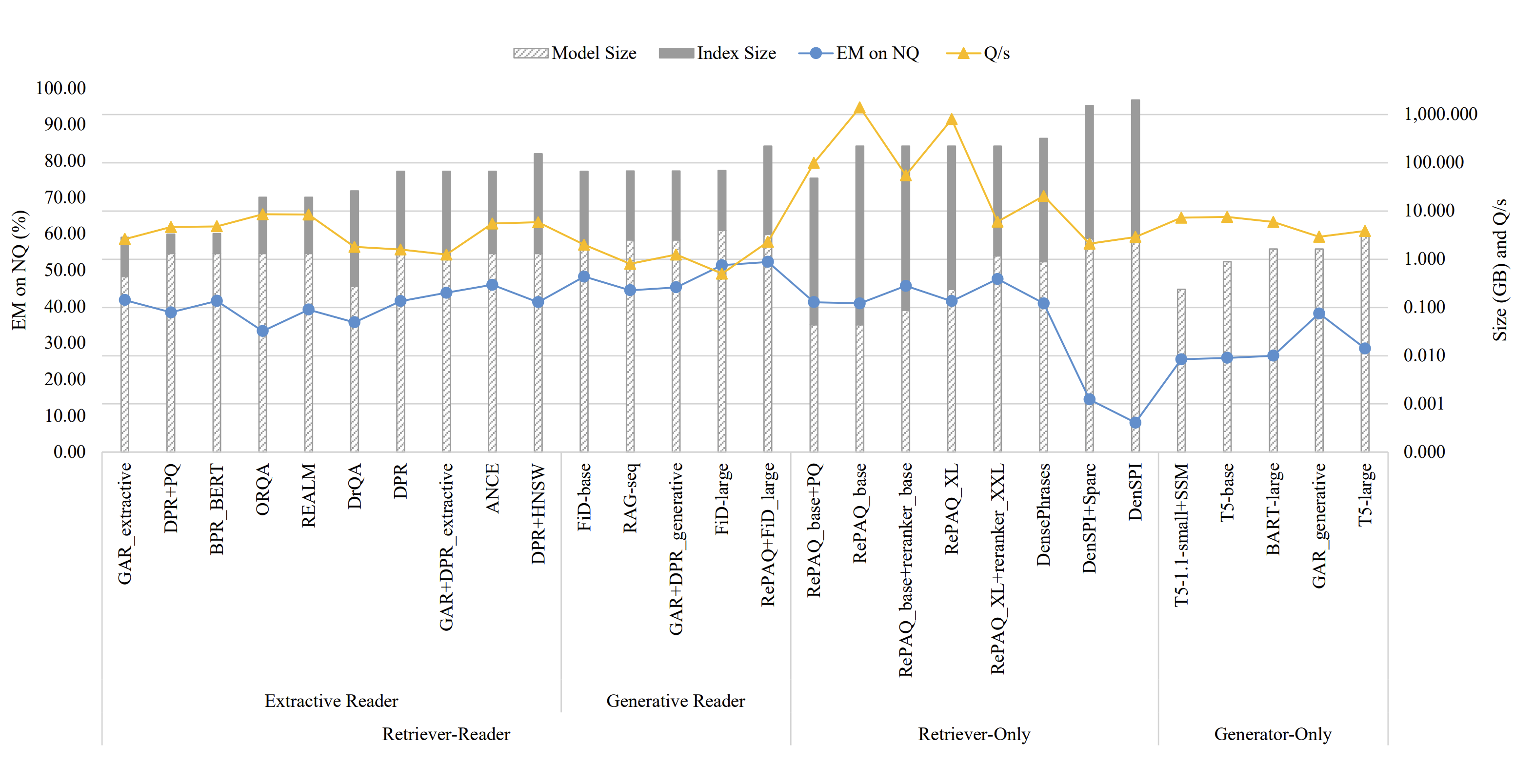
Q. Zhang, S. Chen, D. Xu, Q. Cao, X, Chen, T. Cohn, M. Fang [ACL 2023] The 61th Annual Meeting of the Association for Computational Linguistics We walk through the ODQA models and conclude the core techniques on efficiency. Quantitative analysis on memory cost, processing speed, accuracy and overall comparison are given. |
|
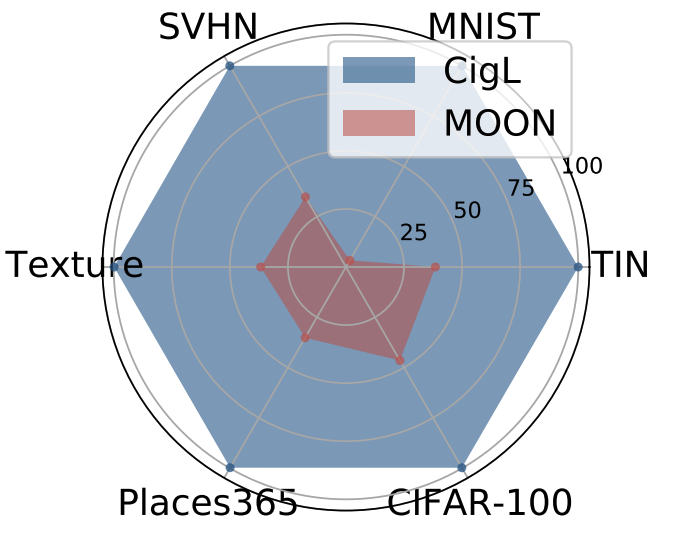
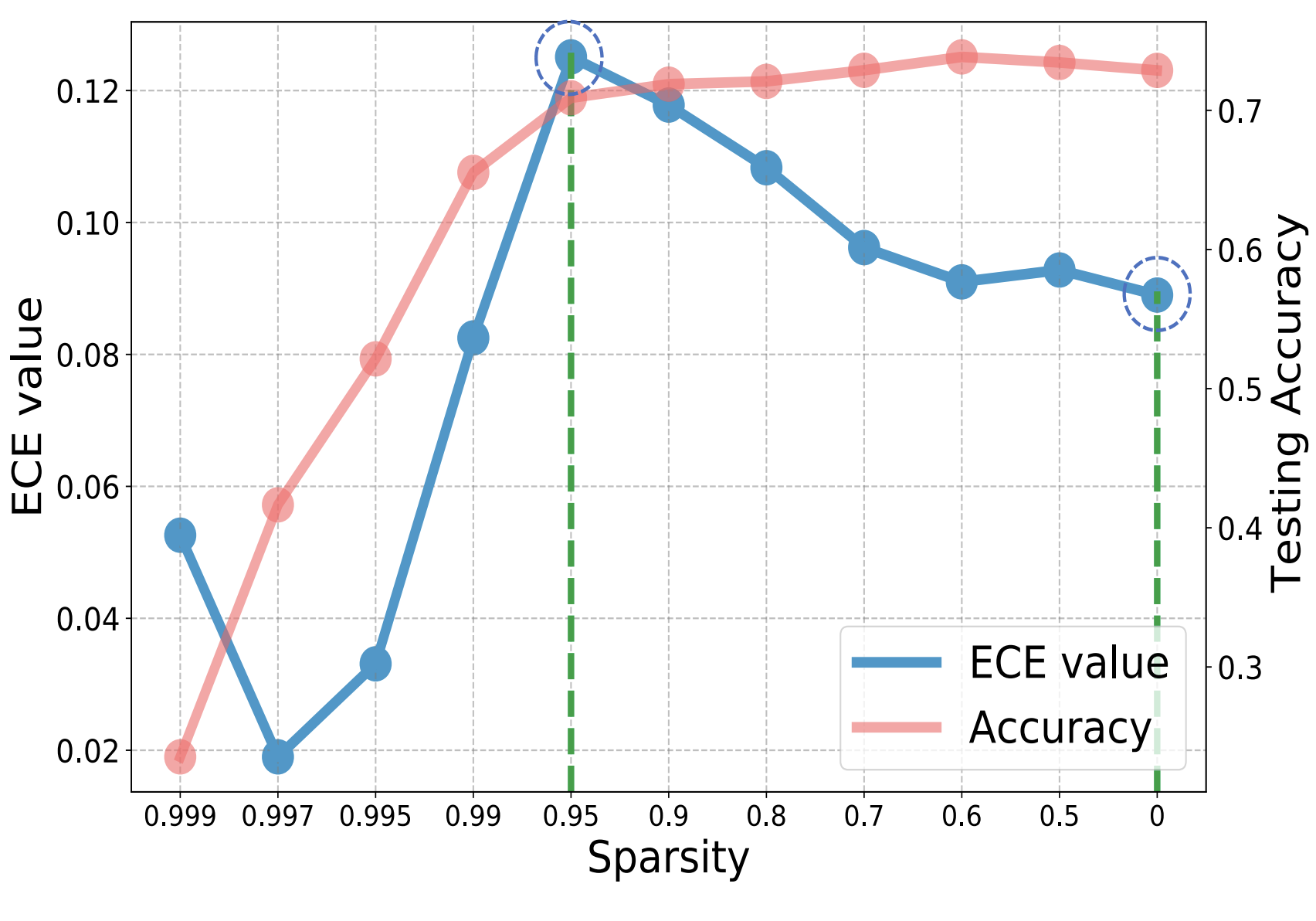
B. Lei, R. Zhang, D. Xu, B. K. Mallick [ICLR 2023] The 11th International Conference on Learning Representations We for the first time identify and study the reliability problem of sparse training and find that sparse training exacerbates the over-confidence problem of DNNs. We then develop a new sparse training method, CigL, to produce more reliable sparse models. |
|
Zihan Dong (Undergrad at NC State), D. Xu [ICAIBD 2023] The 6th International Conference on Artificial Intelligence and Big Data This study explores how ChatGPT personalizes the learning experience, how it can be augmented with math and physical performance, and how educators can ensure that the LLM algorithm is unbiased. |
|
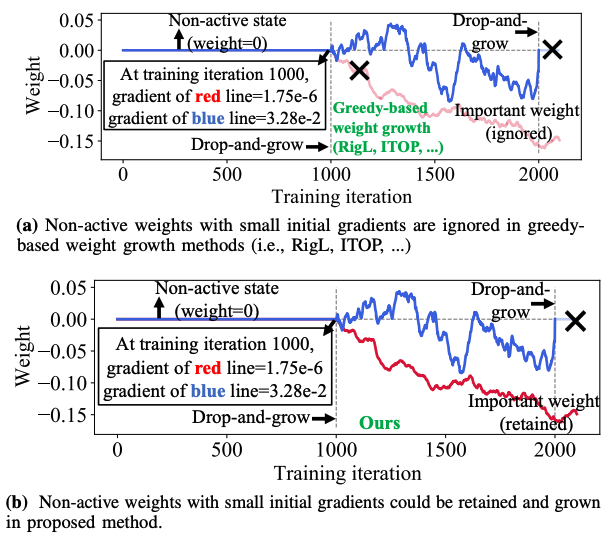
S. Huang, B. Lei, D. Xu, H. Peng, Y. Sun, M. Xie, C. Ding [DAC 2023] The 60th Design Automation Conference To assist explainable sparse training, we propose important weights exploitation and weights coverage exploration to characterize sparse training. Our method does not need to train dense models, achieving up to 95% sparsity ratio and even higher accuracy than dense training, with same amount of iterations. |
|
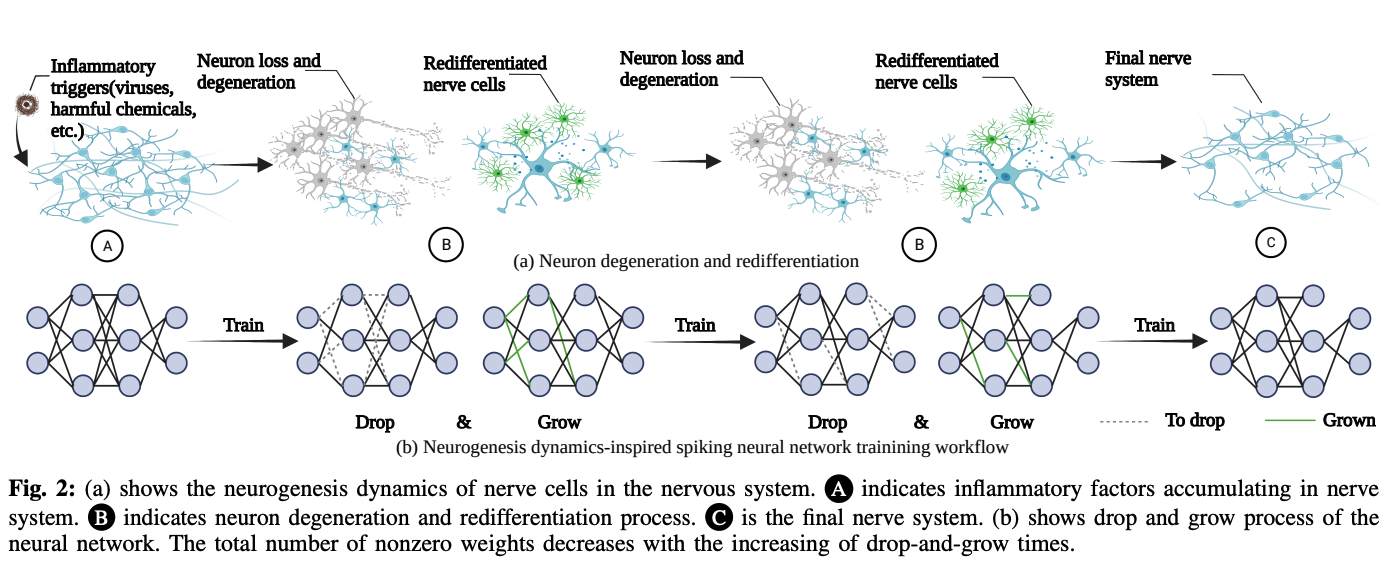
S. Huang, H. Fang, K. Mahmood, B. Lei, N. Xu, B. Lei, Y. Sun, D. Xu, W. Wen, C. Ding [DAC 2023] The 60th Design Automation Conference We propose an energy efficient spiking neural network training workflow, and design a new drop-andgrow strategy with decreasing number of non-zero weights in the process of dynamically updating sparse mask. We demonstrate extremely high sparsity (i.e., 99%) model performance in SNN based vision tasks. |
|
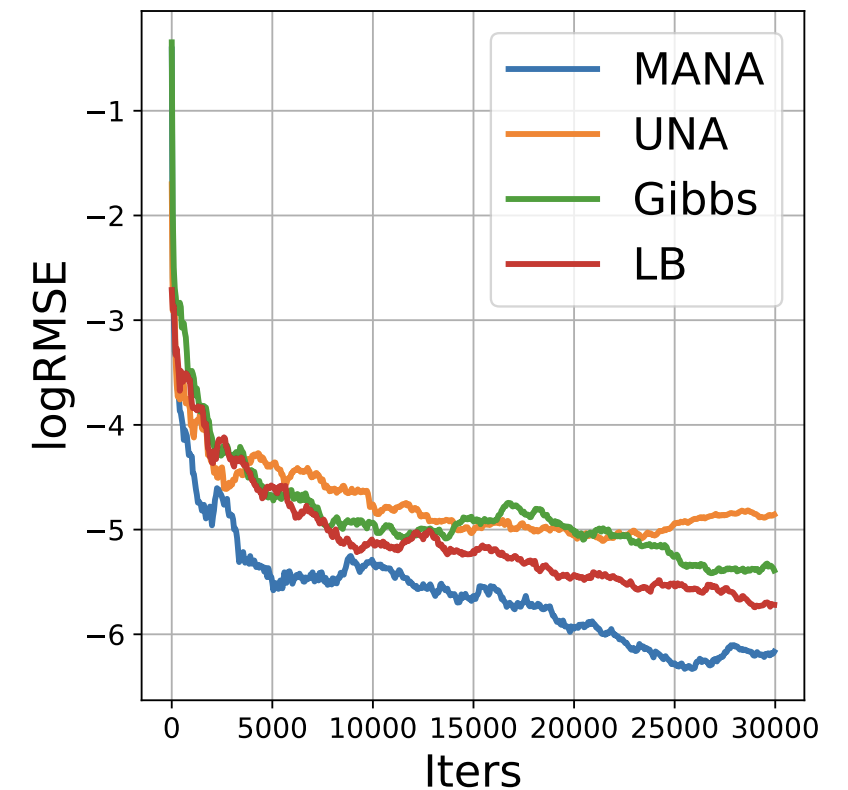
Y. Xiang*, D. Zhu*, B. Lei, D. Xu, R. Zhang [AISTATS 2023] The 26th International Conference on Artificial Intelligence and Statistics We develop a gradient-like proposal for any discrete distribution without this strong requirement. Built upon a locally-balanced proposal, our method efficiently approximates the discrete likelihood ratio via a Newton’s series expansion to enable a large and efficient exploration in discrete spaces. |

|
Y. Tian, W. Gao, Q. Zhang, P. Sun, D. Xu Internet of Things We propose a class-based covariance transfer method from the perspective of disentangling to transfer covariance information in long-tailed classification task. |

|
Y. Xie, Z. Li, H. Bao, X. Jia, D. Xu, X. Zhou, S. Skakun [AAAI 2023] The 37th AAAI International Conference on Artificial Intelligence We propose an autonomous image composition and masking method for cloud masking, a fundamental task in Earth observation problems across social sectors such as agriculture, energy, and water. |
|
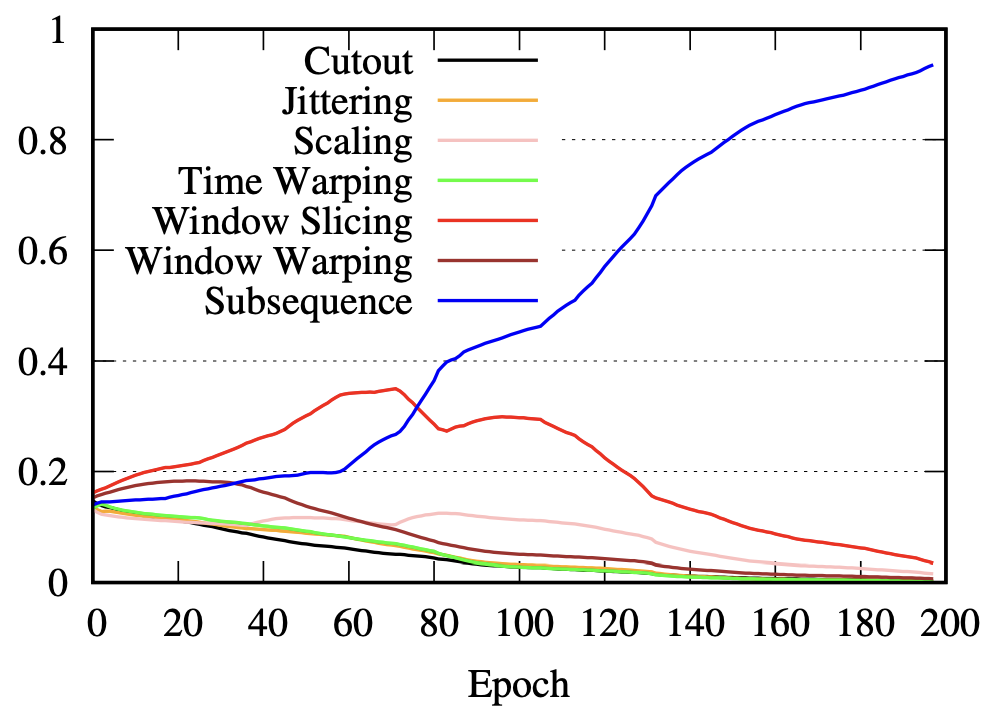
D. Luo, W. Cheng, Y. Wang, D. Xu, J. Ni, W. Yu, X. Zhang, Y. Liu, Y. Chen, H. Chen, X. Zhang [AAAI 2023] The 37th AAAI International Conference on Artificial Intelligence We propose an adaptive data augmentation method to avoid ad-hoc choices or painstakingly trial-and-error tuning for time series representation learning. |
2022 |
|
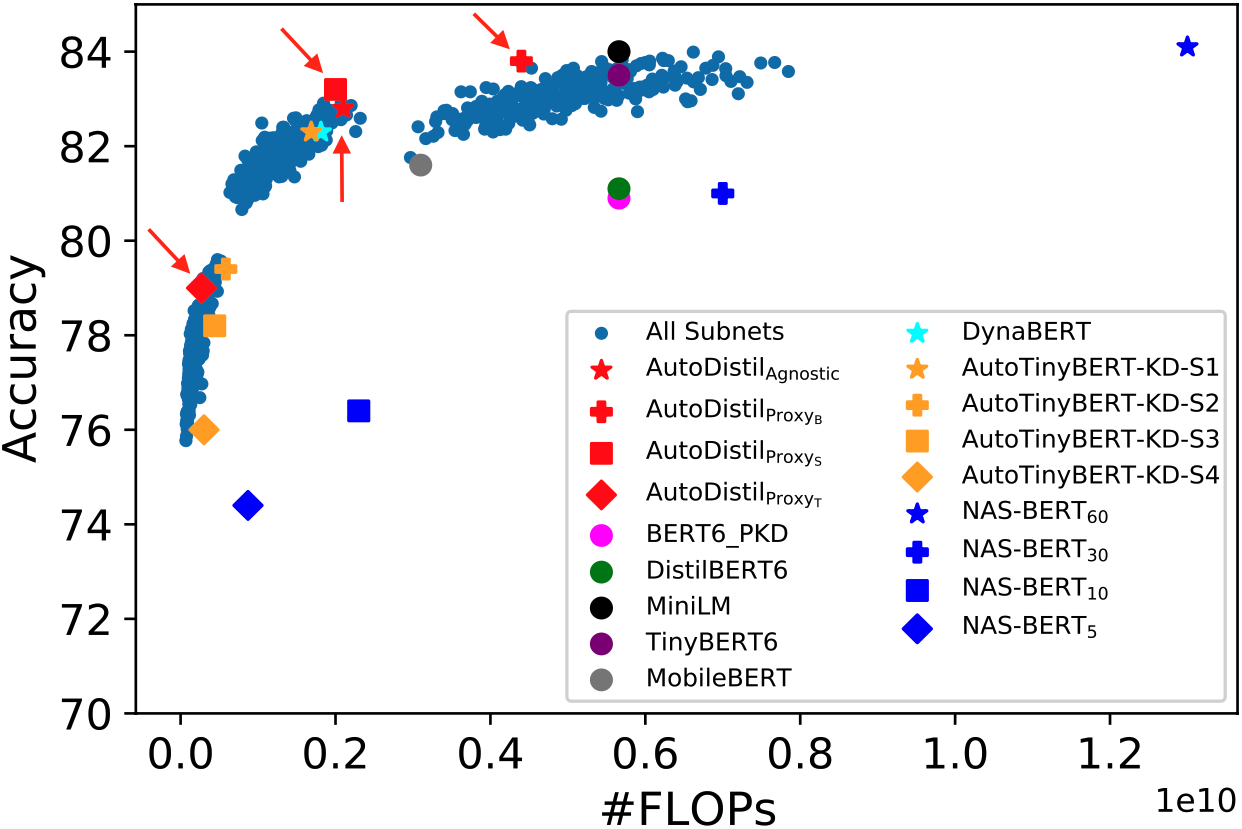
D. Xu, S. Mukherjee, X. Liu, D. Dey, W. Wang, X. Zhang, A. H. Awadallah, J. Gao [NeurIPS 2022] The 36th Conference on Neural Information Processing Systems PDF / Code We develop a few-shot task-agnostic NAS framework, AutoDistil, for distilling large language models into compressed students with variable computational cost. AutoDistil outperforms leading baselines with upto 3x additional reduction in computational cost and negligible loss in task performance. |
|
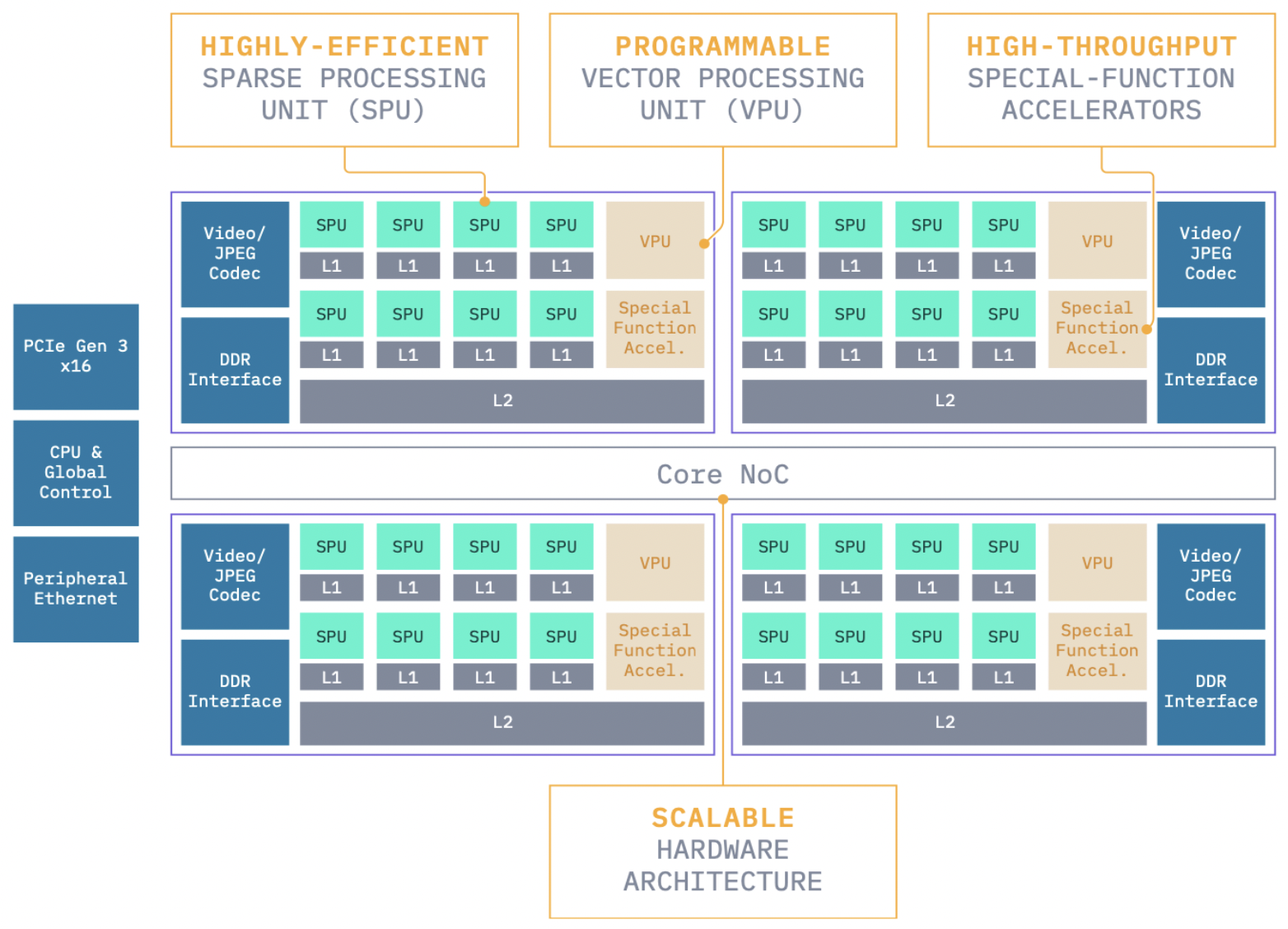
I. E. Yen, Z. Xiao, D. Xu [SNN 2022] Sparsity in Neural Networks 2022 Workshop PDF / Code / Supp / Slides We introduce the first commercial hardware platform supporting high-degree sparsity acceleration up to 32 times — S4. S4 provides a (sparse) equivalent computation power of 944 TOPS in INT8 and 472 TFLOPS in BF16, and has 20GB LPDDR4 memory with up to 72 GB memory bandwidth in a low 70 Watt power envelope. We demonstrate several-times practical inference speedup on S4 over mainstream inference platforms such as Nvidia T4. |
|
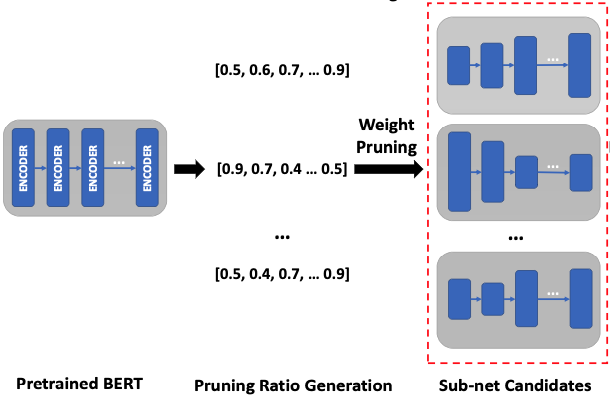
S. Huang, N. Liu, Y. Liang, H. Peng, H. Li, D. Xu, M. Xie, C. Ding [ISQED 2022] The 23rd IEEE International Society for Quality Electronic Design Video / PDF / Code / Supp / Slides We propose AE-BERT, an automatic and efficient pruning framework. AE-BERT achieves the inference time of a single BERT-BASE encoder on Xilinx Alveo U200 FPGA board that is 1.83x faster compared to Intel(R) Xeon(R) Gold 5218 (2.30GHz) CPU. |
|
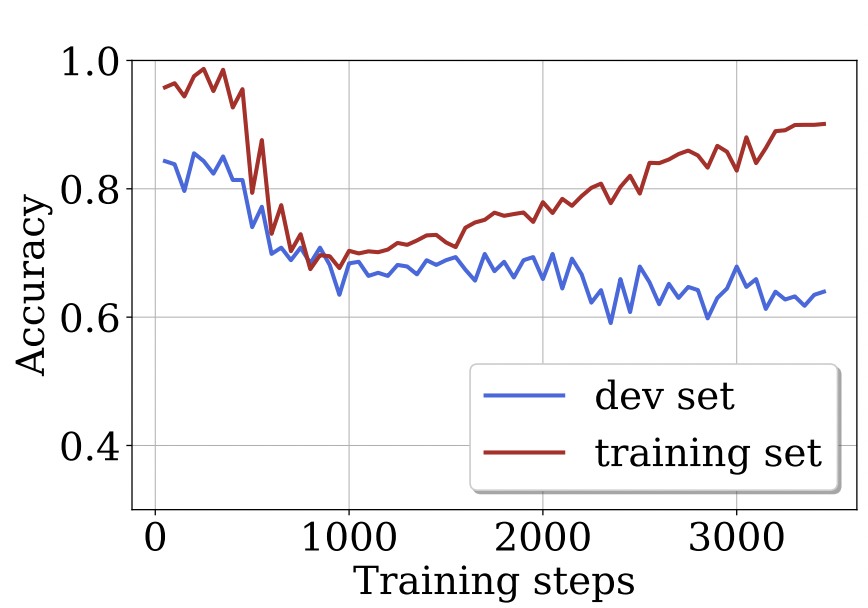
S. Huang*, D. Xu*, I. E. Yen, S. Chang, B. Li, C. Ding, et al. [ACL 2022] The 60th Annual Meeting of the Association for Computational Linguistics PDF / Code / Supp / Slides We study network pruning of Transformer-based language models under the pre-training and fine-tuning paradigm and propose a counter-traditional hypothesis that pruning increases the risk of overfitting when performed during the fine-tuning phase. |
2021 |
|
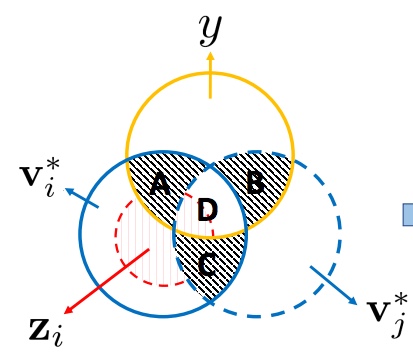
D. Xu, W. Cheng, D. Luo, H. Chen, X. Zhang [NeurIPS 2021] The 35th Conference on Neural Information Processing Systems PDF / Code / Supp / Slides We propose an information-aware contrastive learning framework for graph-structure data, and show for the first time that all recent graph contrastive learning methods can be unified by our framework. |
|
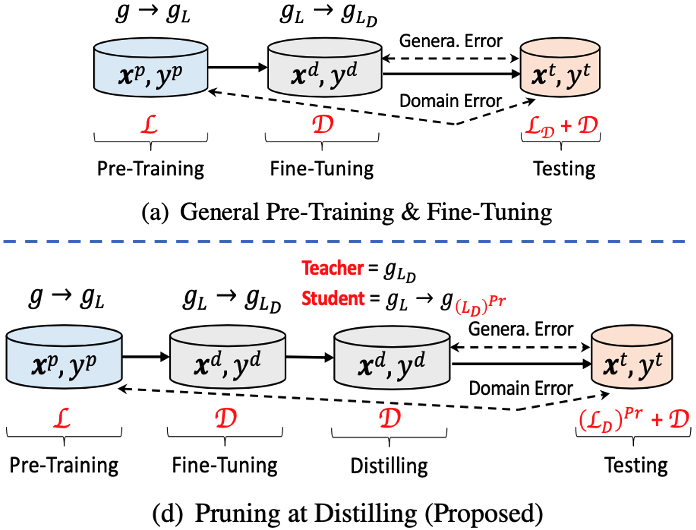
Dongkuan Xu, Ian En-Hsu Yen, Jinxi Zhao, Zhibin Xiao [NAACL-HLT 2021] 2021 Annual Conference of the North American Chapter of the Association for Computational Linguistics PDF / Code / Supp / Slides We study how knowledge is transferred and lost during the pre-train, fine-tune, and pruning process, and propose a knowledge-aware sparse pruning process that achieves significantly superior results than existing literature. |
|
Xin Dong, Yaxin Zhu, Zuohui Fu, Dongkuan Xu, Gerard de Melo [ACL 2021] The 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing PDF / Code / Supp / Slides We study data augmentation for cross-lingual natural language inference and propose two methods of training a generative model to induce synthesized examples to reflect more diversity in a semantically faithful way. |
|
Dongkuan Xu, Wei Cheng, Jingchao Ni, Dongsheng Luo, Masanao Natsumeda, Dongjin Song, Bo Zong, Haifeng Chen, Xiang Zhang [SDM 2021] The 21th SIAM International Conference on Data Mining PDF / Code / Supp / Slides We utilize multi-instance learning to model the uncertainty of precursor period, and design a contrastive loss to address the issue that annotated anomalies are few. |
|
Dongkuan Xu, Wei Cheng, Xin Dong, Bo Zong, Wenchao Yu, Jingchao Ni, Dongjin Song, Xuchao Zhang, Haifeng Chen, Xiang Zhang [AAAI 2021] The 35th AAAI International Conference on Artificial Intelligence PDF / Code / Supp / Slides We propose MT-RMN to dynamically learn task relationships and accordingly learn to assemble composable modules into complex layouts to jointly solve multiple sequence processing tasks. |
|
Dongkuan Xu, Junjie Liang, Wei Cheng, Hua Wei, Haifeng Chen, Xiang Zhang [AAAI 2021] The 35th AAAI International Conference on Artificial Intelligence PDF / Code / Supp / Slides We propose TRRN to model temporal networks by employing transformer-style self-attention to reason over a set of memories. |
|
Hua Wei, Dongkuan Xu, Junjie Liang, Zhenhui Li [AAAI 2021] The 35th AAAI International Conference on Artificial Intelligence PDF / Code / Supp / Slides We propose MoveSD to model state transition in human movement from a novel perspective, by learning the decision model and integrating the system dynamics. |
|
Junjie Liang, Yanting Wu, Dongkuan Xu, Vasant Honavar [AAAI 2021] The 35th AAAI International Conference on Artificial Intelligence PDF / Code / Supp / Slides We introduce Longitudinal deep kernel Gaussian process regression to fully automate the discovery of complex multi level correlation structure from longitudinal data. |
2020 |
|
Dongsheng Luo, Wei Cheng, Dongkuan Xu, Wenchao Yu, Bo Zong, Haifeng Chen, Xiang Zhang [NeurIPS 2020] The 34th Conference on Neural Information Processing Systems PDF / Code / Supp / Slides We propose to adopt deep neural networks to parameterize the generation process of explanations, which enables a natural approach to multi-instance explanations. |
|
Xin Dong, Yaxin Zhu, Yupeng Zhang, Zuohui Fu, Dongkuan Xu, Sen Yang, Gerard de Melo [SIGIR 2020] The 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval PDF / Code / Supp / Slides We propose a semi-supervised adversarial perturbation framework that encourages the model to be more robust towards such divergence and better adapt to the target language. |
|
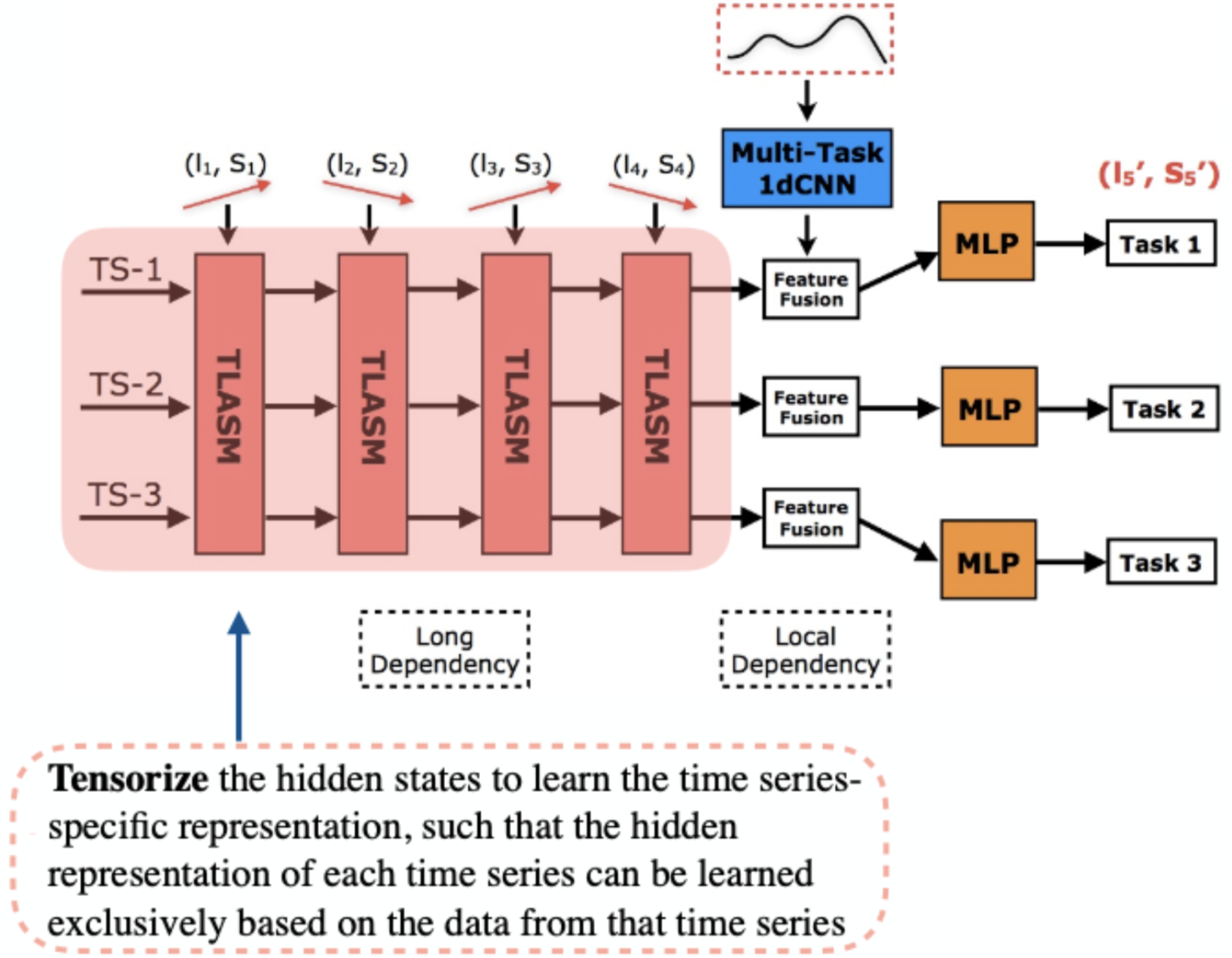
Dongkuan Xu, Wei Cheng, Bo Zong, Dongjin Song, Jingchao Ni, Wenchao Yu, Yanchi Liu, Haifeng Chen, Xiang Zhang [AAAI 2020] The 34th AAAI International Conference on Artificial Intelligence PDF / Code / Poster / Slides We propose a deep architecture for learning trends in multivariate time series, which jointly learns both local and global contextual features for predicting the trend of time series. |
|
Junjie Liang, Dongkuan Xu, Yiwei Sun, Vasant Honavar [AAAI 2020] The 34th AAAI International Conference on Artificial Intelligence PDF / Code / Supp We propose longitudinal kulti-level factorization machine, to the best of our knowledge, the first model to address these challenges in learning predictive models from longitudinal data. |
2019 |
|
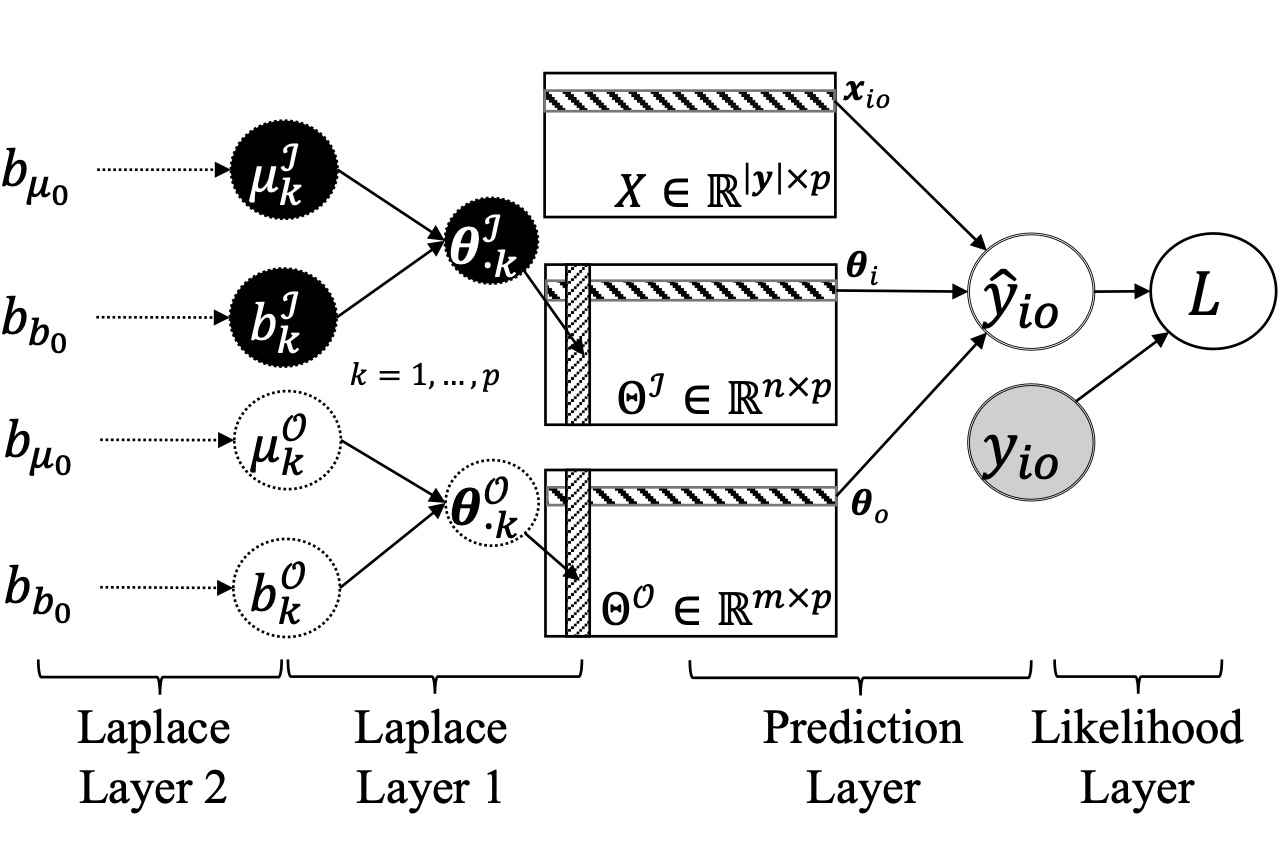
Dongkuan Xu, Wei Cheng, Dongsheng Luo, Yameng Gu, Xiao Liu, Jingchao Ni, Bo Zong, Haifeng Chen, Xiang Zhang [ICDM 2019] The 19th IEEE International Conference on Data Mining PDF / Slides We propose an adaptive neural network for node classification in dynamic networks, which is able to consider the evolution of both node attributes and network topology. |
|
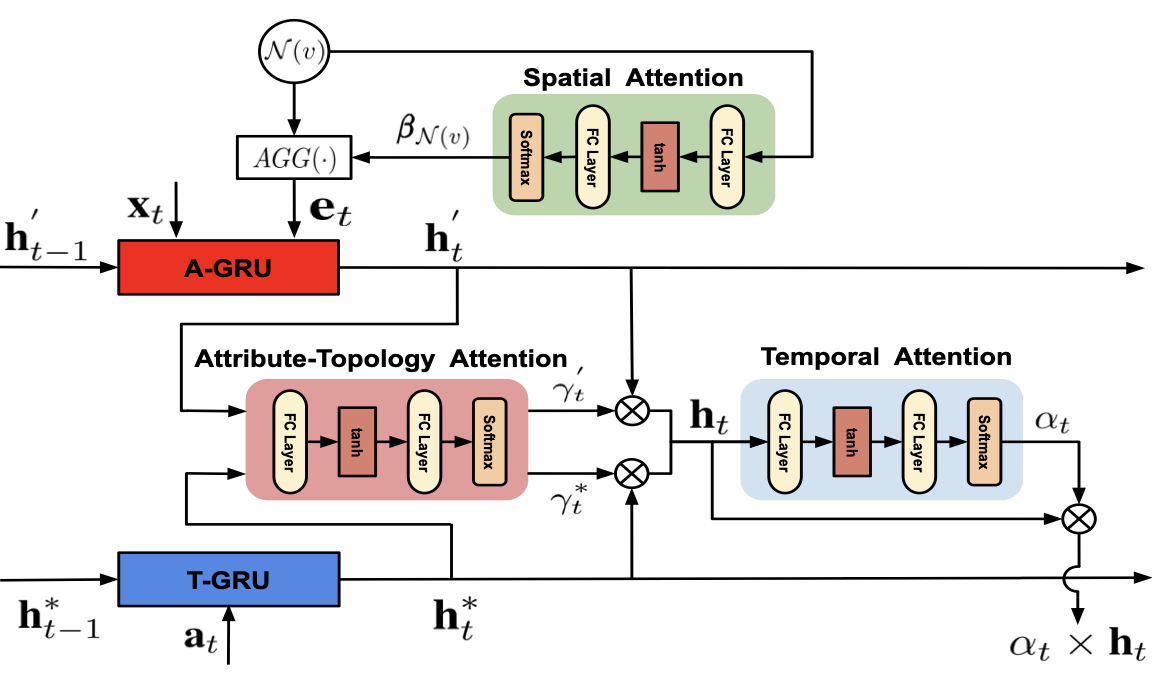
Dongkuan Xu, Wei Cheng, Dongsheng Luo, Xiao Liu, Xiang Zhang [IJCAI 2019] The 29th International Joint Conference on Artificial Intelligence PDF / Code / Poster / Slides We propose a spatio-temporal attentive RNN model, which aims to learn node representations for classification by jointly considering both the temporal and spatial patterns of the node. |
|
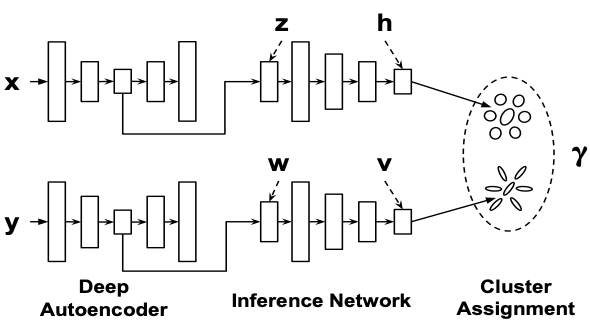
Dongkuan Xu, Wei Cheng, Dongsheng Luo, Xiao Liu, Xiang Zhang [SDM 2019] The 19th SIAM International Conference on Data Mining PDF / Code / Supp / Poster / Slides DeepCC utilizes the deep autoencoder for dimension reduction, and employs a variant of Gaussian mixture model to infer the cluster assignments. A mutual information loss is proposed to bridge the training of instances and features. |
2018 |
|
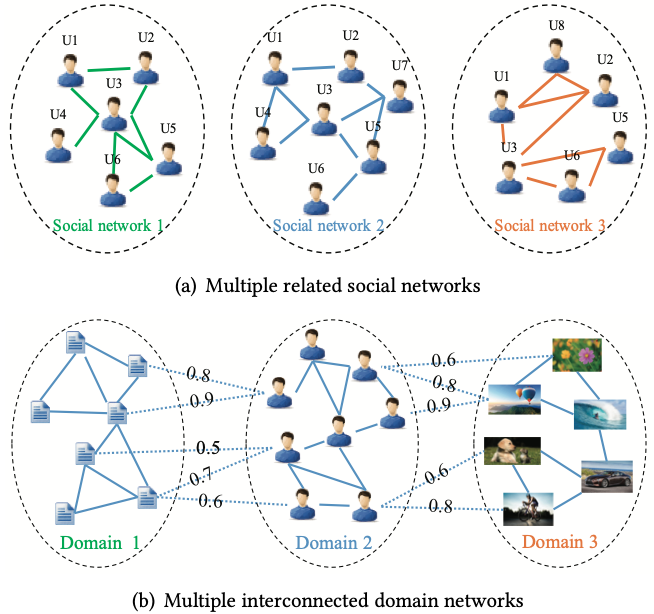
Jingchao Ni, Shiyu Chang, Xiao Liu, Wei Cheng, Haifeng Chen, Dongkuan Xu and Xiang Zhang [WWW 2018] The 27th International Conference on World Wide Web PDF / Code DMNE coordinates multiple neural networks (one for each input network data) with a co-regularized loss function to manipulate cross-network relationships, which can be many-to-many, weighted and incomplete. |
|
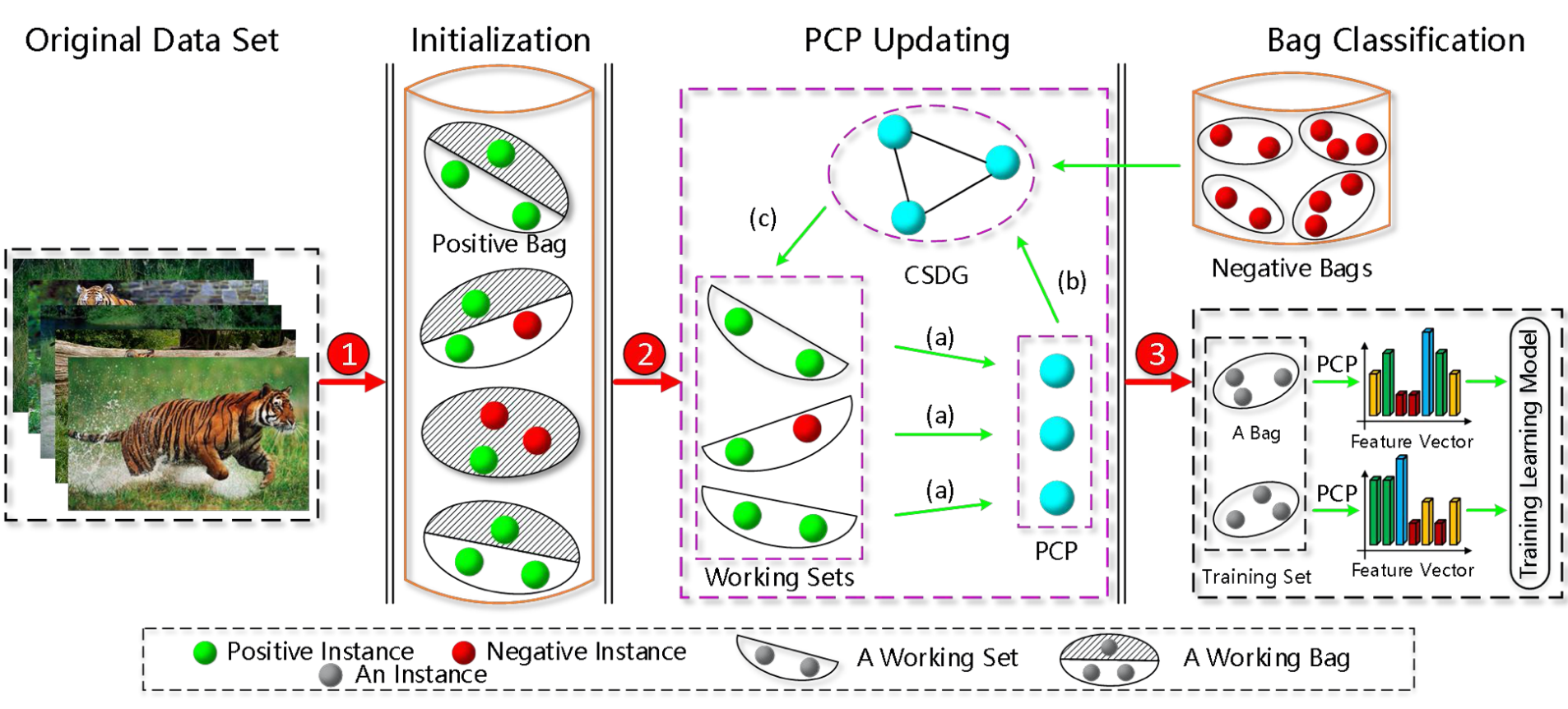
Dongkuan Xu, Wei Zhang, Jia Wu, Yingjie Tian, Qin Zhang, Xindong Wu arXiv preprint Most multi-instance learning (MIL) methods that study true positive instances ignore 1) the global similarity among positive instances and 2) that negative instances are non-i.i.d.. We propose a MTL method based on positive instance graph updating to address this issue. |
|
Yingjie Tian, Dongkuan Xu, Chunhua Zhang Operations Research Transactions, 2018 This paper reviews the research progress of multi-instance learning (MTL), introduces different assumptions, and categories MTL methods into instance-level, bag-level, and embedded-space. Extensions and major applications in various areas are discussed at last. |
2017 |

|
Dongkuan Xu, Jia Wu, Dewei Li, Yingjie Tian, Xingquan Zhu, Xindong Wu Pattern Recognition, 2017 We propose a self-adaptive locality-sensitive hashing encoding method for multi-instance learning (MIL), which efficiently deals with large MIL problems. |
|
Dewei Li, Dongkuan Xu, Jingjing Tang, Yingjie Tian [IJCNN 2017] The 30th IEEE International Joint Conference on Neural Networks We propose a metric learning method for multi-instance classification, aiming to find an instance-dependent metric by maximizing the relative distance on neighborhood level. |
2016 |
|
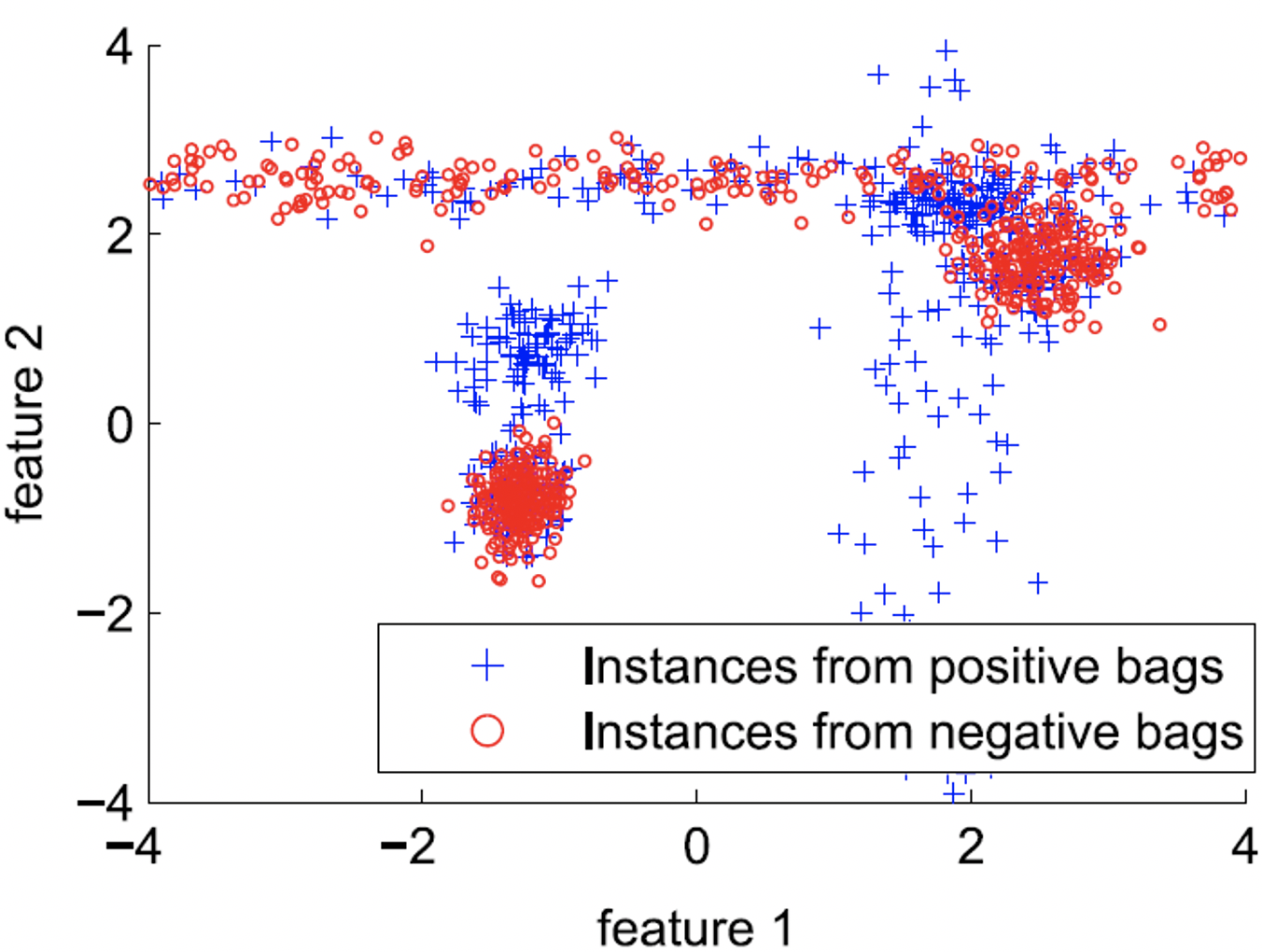
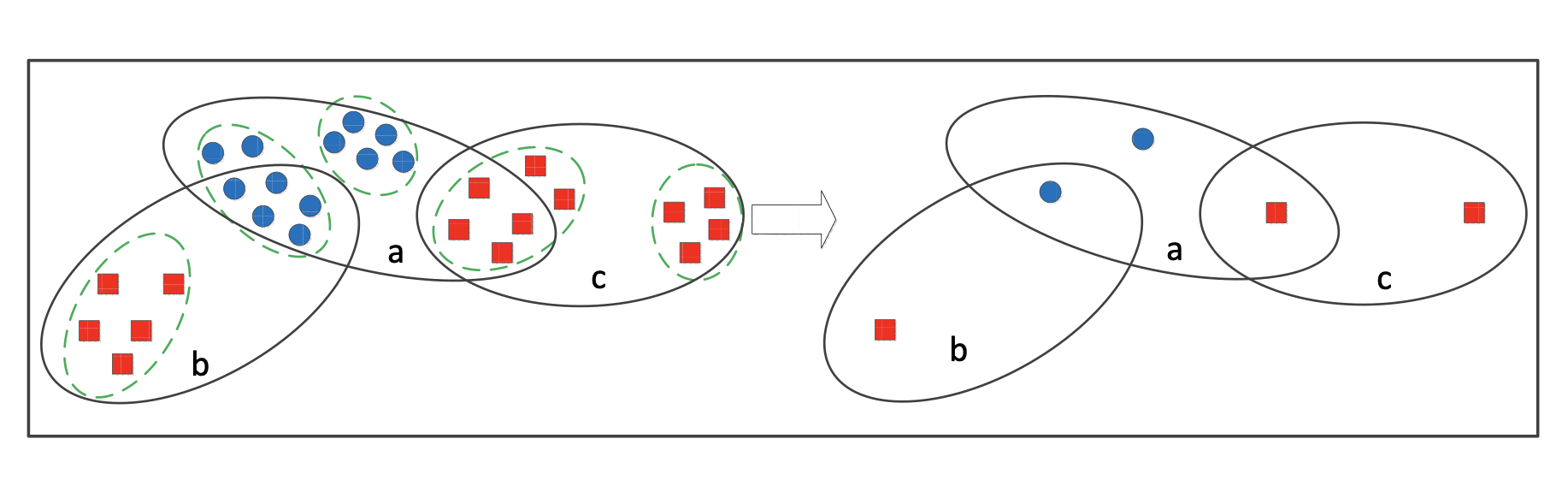
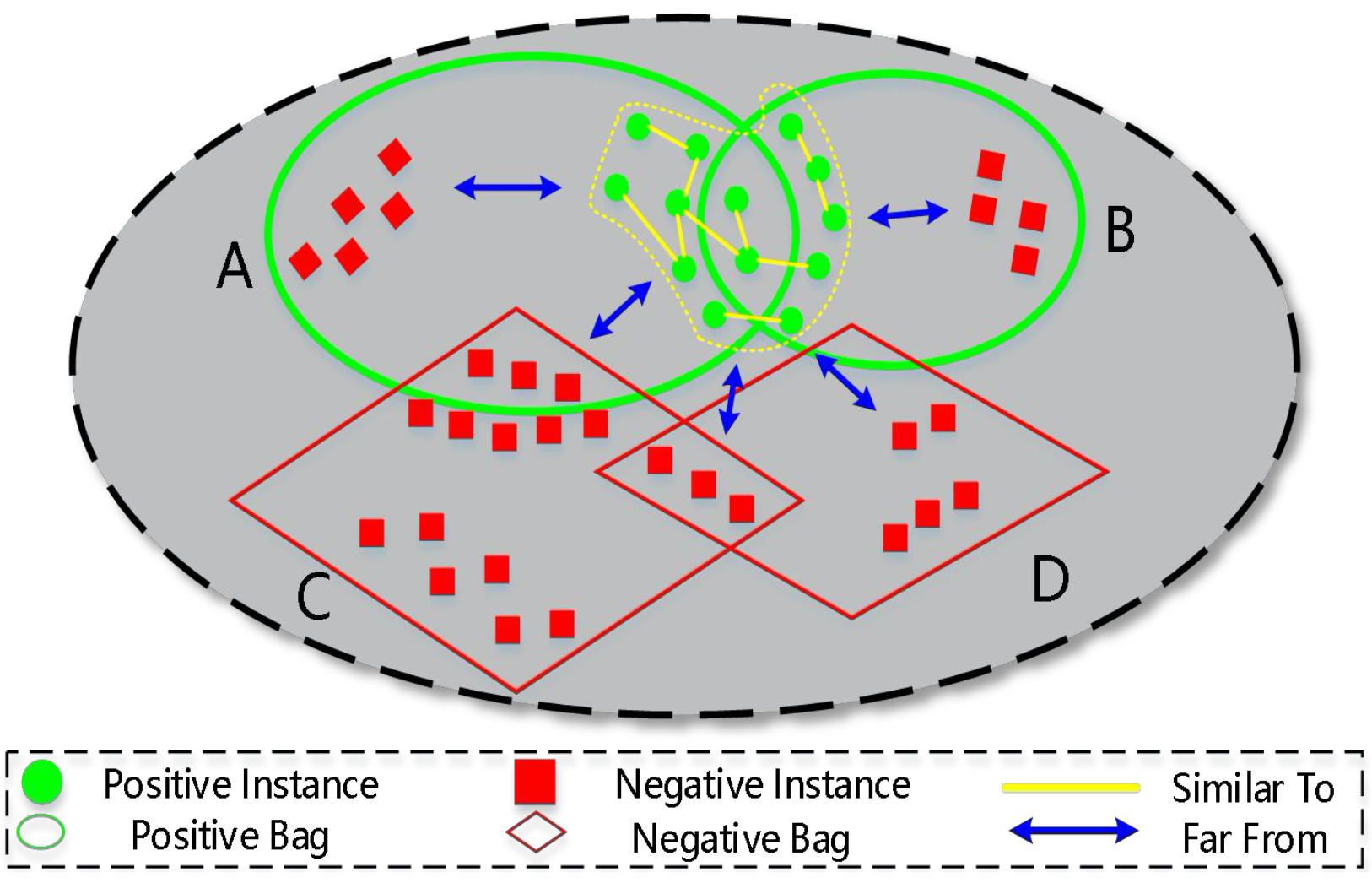
Dongkuan Xu, Jia Wu, Wei Zhang, Yingjie Tian arXiv preprint arXiv:1612.03550, 2016 We propose a positive instance detection method based on multiple instance learning, of which the core idea is that true positive instances should not only be similar to themselves globally but also different from negative instances robustly. |
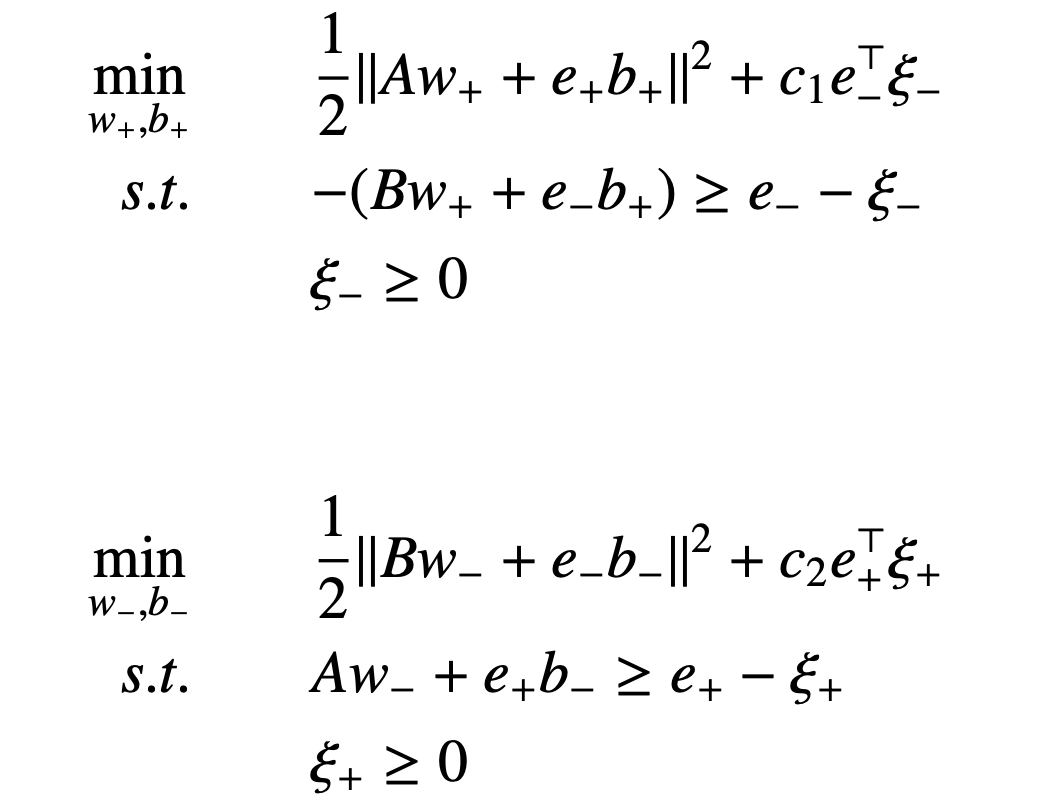
|
Dewei Li, Wei Zhang, Dongkuan Xu, Yingjie Tian [ITQM 2016] The 4th International Conference on Information Technology and Quantitative Management PDF (Best Paper Award) We propose a metric learning approach called multi-metrics classification machine. We establish an optimization problem for each class (each metric) to learn multiple metrics independently. |
2015 |
|
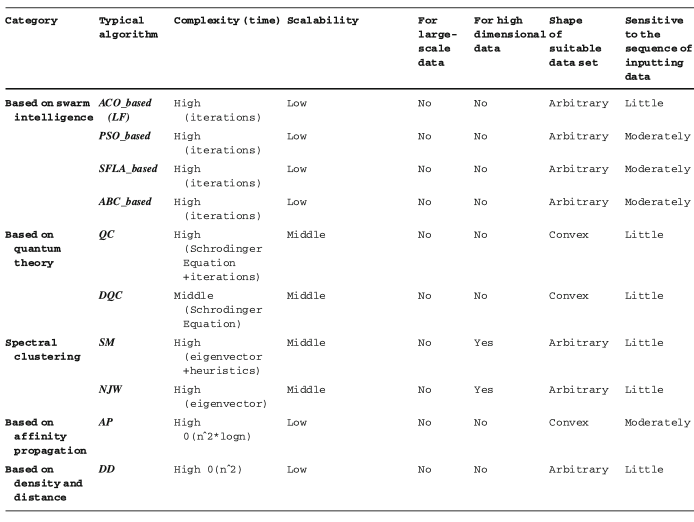
Dongkuan Xu, Yingjie Tian Annals of Data Science, 2015 We introduce the definition of clustering, the basic elements involved in clustering process, and categorize the clustering algorithms into the traditional ones and the modern ones. All the algorithms are discussed comprehensively. |
Undergraduate |
|
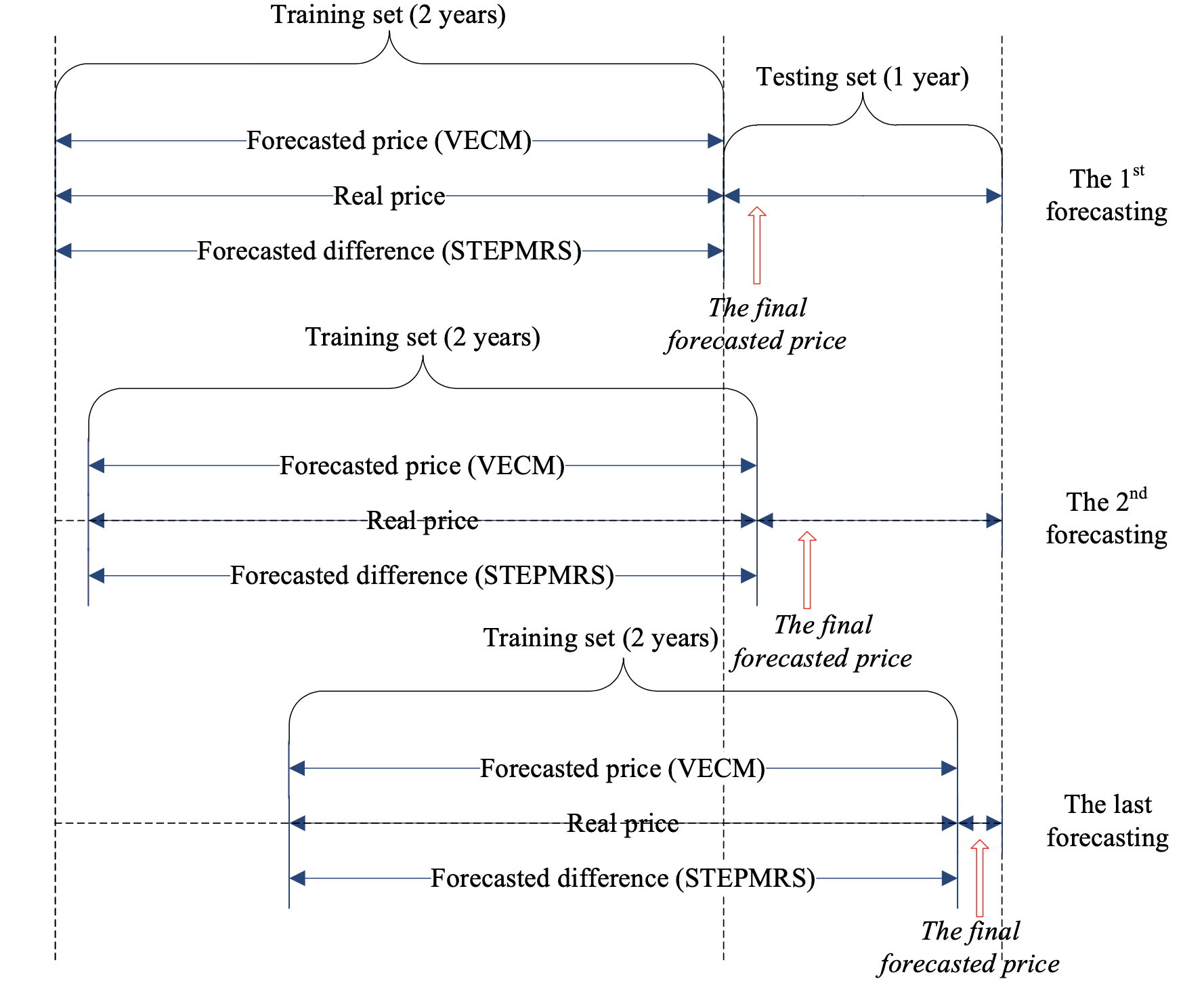
Dongkuan Xu, Tianjia Chen, Wei Xu International Journal of Global Energy Issues, 2015 This paper proposes a support vector machine-based ensemble model to forecast crude oil price based on VECM and stochastic time effective pattern modelling and recognition system (STEPMRS). |
|
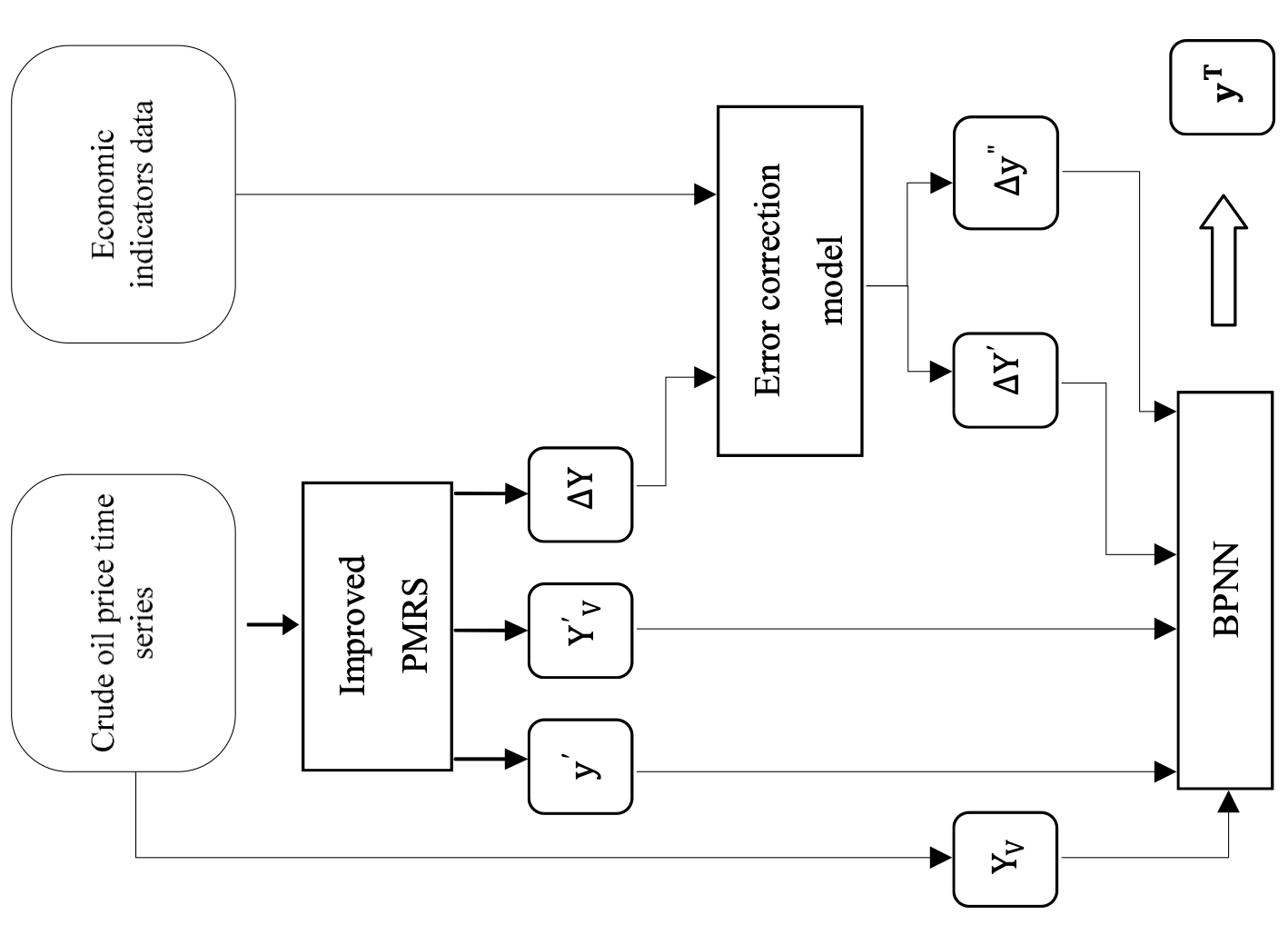
Dongkuan Xu, Yi Zhang, Cheng Cheng, Wei Xu, Likuan Zhang [HICSS 2014] The 47th Hawaii International Conference on System Science This paper presents an integrated model to forecast crude oil prices, where pattern modelling & recognition system is used to model the price trend and error correction model is offered to forecast errors. A neural network layer is employed to integrate the results. |
|
*Last updated on 03/15/2026* |